Разница между типами разрыва линии CR LF, LF и CR?
Я хотел бы знать разницу (с примерами, если это возможно) между типами разрыва строки CR LF (Windows), LF (Unix) и CR (Macintosh).
9 ответов
больше информации, как всегда, на Википедия.
CR и LF являются управляющими символами, соответственно закодированными 0x0D (13 десятичных знаков) и 0x0A (10 десятичное).
Они используются для обозначения разрыва строки в текстовом файле. Как вы указали, Windows использует два символа последовательности CR LF; Unix использует только LF, а старый MacOS (pre-OSX MacIntosh) использовал CR.
апокрифическая историческая перспектива:
как отметил Петр, CR = Возврат Каретки и LF = Строки, два выражения имеют свои корни в старых пишущих машинках / TTY. LF переместил бумагу вверх (но сохранил горизонтальное положение идентичным), а CR вернул «каретку» так, чтобы следующий введенный символ был в крайнем левом положении на бумаге (но на той же строке). CR+LF делал и то, и другое, то есть готовился ввести новую строку. С течением времени физическая семантика кодов была неприменима, а поскольку память и дискетное пространство были в цене, некоторые ОС дизайнеры решили использовать только одного из персонажей, они просто не очень хорошо общались друг с другом 😉
большинство современных текстовых редакторов и текстовых приложений предлагают опции / настройки и т. д. это позволяет автоматически обнаруживать соглашение о конце строки файла и отображать его соответствующим образом.
это хорошее резюме, которое я нашел:
поскольку нет ответа, заявляющего только это, кратко резюмировал:
Возврат Каретки (Mac pre-OSX)
Строки (Linux, MAC OSX)
возврат каретки и подача линии (Windows)
Если вы видите код ASCII в странном формате, это просто число 13 и 10 в другом радиксе/базе, обычно база 8 (восьмеричная) или база 16 (шестнадцатеричная).
у Джеффа Этвуда есть недавнее сообщение в блоге об этом:Великий Раскол Новой Линии
последовательность CR+LF была в общем использовании на многих ранних компьютерных системах приняла телетайпная машин, обычно ASR33, как консоль устройства, потому что эта последовательность была требуется разместить эти принтеры на начало новой линии. На этом системы, текст часто регулярно состоящий быть совместимым с этими принтеры, начиная с концепции устройства драйверы, скрывающие такие детали оборудования из приложения еще не было хорошо разработано; приложения должны были говорить прямо на телетайп и следовать конвенциям. разделение из двух функций скрыты факт, что печатающая головка не могла возвращение из крайнего правого начало следующей строки время одного персонажа. Вот почему последовательность всегда отправлялась с CR первый. На самом деле, это часто необходимо чтобы отправить лишние символы (лишние CRs или NULs, которые игнорируются) для дайте печатающей головке время перейти к левое поле. даже после телетайпов были заменены компьютерные терминалы с более высокими скоростями передачи данных, много работая системы по-прежнему поддерживаются автоматически отправка этих символов заполнения, для совместимость с более дешевыми терминалами это потребовало несколько раз символов для прокрутки экрана.
теоретически CR возвращает курсор в первую позицию (слева). LF подает одну строку, перемещая курсор на одну строку вниз. Вот как в старые времена вы управляли принтерами и текстовыми мониторами. Эти символы обычно используются для обозначения конца строк в текстовых файлах. В разных операционных системах используются разные соглашения. Как вы указали, Windows использует комбинацию CR/LF, а pre-OSX Mac использует только CR и так далее.
системы на основе ASCII или a совместимый набор символов, использовать если (Линия подачи, 0x0A, 10 в десятичном) или CR (возврат каретки, 0x0D, 13 в десятичном) индивидуально, или CR следовать LF (CR+LF, 0x0D 0x0A); Эти символы основаны на командах принтера: подача строки указано, что одна строка бумага должна подаваться из принтера, а каретка-возвращаться указано, что принтер перевозка должна возвратиться к началу течения линия.
печальное состояние «разделителей записей» или «линейных Терминаторов» является наследием темных веков вычислений.
теперь мы считаем само собой разумеющимся, что все, что мы хотим представить, является каким-то образом структурированными данными и соответствует различным абстракциям, которые определяют строки, файлы, протоколы, сообщения, разметку, что угодно.
но когда-то это было не совсем так. Применения встроенные характеры управления и прибор-специфическая обработка. Мозг-мертвые системы, которые требовали и CR, и LF просто не имели абстракции для разделителей записей или линейных Терминаторов. CR был необходим для того, чтобы заставить телетайп или видеодисплей вернуться в столбец один, а LF (сегодня, NL, тот же код) был необходим, чтобы заставить его перейти к следующей строке. Я думаю, идея сделать что-то другое, кроме сброса необработанных данных на устройство, была слишком сложной.
Unix и Mac фактически указали абстрагирование для конца линии, представьте себе это. К сожалению, они уточнили разные. (Unix, кхм, пришел первым.) И, естественно, они использовали код управления, который уже был «близок» к S. O. P.
поскольку почти все наше операционное программное обеспечение сегодня является потомком Unix, Mac или MS operating SW, мы застряли с линией, заканчивающейся путаницей.
NL, полученный из EBCDIC NL = x ’15’, который логически сравнивался бы с CRLF x’odoa ascii. это становится очевидным, когда physcally перемещение данных с мейнфреймов на сч. Coloquially (как только тайные люди используют ebcdic) NL был приравнен к CR или LF или CRLF
Коды ASCII символов
Управляющие символы (большинство непечатные; наиболее важные подсвечены жёлтым)
Печатные символы (стандартные)
| Символ | Dec | Hex | Oct | Описание |
|---|---|---|---|---|
| 32 | 20 | 040 | Пробел | |
| ! | 33 | 21 | 041 | Восклицательный знак |
| « | 34 | 22 | 042 | Кавычка (» в HTML) |
| # | 35 | 23 | 043 | Решётка (знак числа) |
| $ | 36 | 24 | 044 | Доллар |
| % | 37 | 25 | 045 | Проценты |
| & | 38 | 26 | 046 | Амперсанд |
| ‘ | 39 | 27 | 047 | Закрывающая одиночная кавычка (апостроф) |
| ( | 40 | 28 | 050 | Открывающая скобка |
| ) | 41 | 29 | 051 | Закрывающая скобка |
| * | 42 | 2a | 052 | Звёздочка, умножение |
| + | 43 | 2b | 053 | Плюс |
| , | 44 | 2c | 054 | Запятая |
| — | 45 | 2d | 055 | Дефис, минус |
| . | 46 | 2e | 056 | Точка |
| / | 47 | 2f | 057 | Наклонная черта (слеш, деление) |
| 0 | 48 | 30 | 060 | Ноль |
| 1 | 49 | 31 | 061 | Один |
| 2 | 50 | 32 | 062 | Два |
| 3 | 51 | 33 | 063 | Три |
| 4 | 52 | 34 | 064 | Четыре |
| 5 | 53 | 35 | 065 | Пять |
| 6 | 54 | 36 | 066 | Шесть |
| 7 | 55 | 37 | 067 | Семь |
| 8 | 56 | 38 | 070 | Восемь |
| 9 | 57 | 39 | 071 | Девять |
| : | 58 | 3a | 072 | Двоеточие |
| ; | 59 | 3b | 073 | Точка с запятой |
| 62 | 3e | 076 | Знак больше | |
| ? | 63 | 3f | 077 | Знак вопроса |
| @ | 64 | 40 | 100 | эт, собака |
| A | 65 | 41 | 101 | Заглавная A |
| B | 66 | 42 | 102 | Заглавная B |
| C | 67 | 43 | 103 | Заглавная C |
| D | 68 | 44 | 104 | Заглавная D |
| E | 69 | 45 | 105 | Заглавная E |
| F | 70 | 46 | 106 | Заглавная F |
| G | 71 | 47 | 107 | Заглавная G |
| H | 72 | 48 | 110 | Заглавная H |
| I | 73 | 49 | 111 | Заглавная I |
| J | 74 | 4a | 112 | Заглавная J |
| K | 75 | 4b | 113 | Заглавная K |
| L | 76 | 4c | 114 | Заглавная L |
| M | 77 | 4d | 115 | Заглавная M |
| N | 78 | 4e | 116 | Заглавная N |
| O | 79 | 4f | 117 | Заглавная O |
| P | 80 | 50 | 120 | Заглавная P |
| Q | 81 | 51 | 121 | Заглавная Q |
| R | 82 | 52 | 122 | Заглавная R |
| S | 83 | 53 | 123 | Заглавная S |
| T | 84 | 54 | 124 | Заглавная T |
| U | 85 | 55 | 125 | Заглавная U |
| V | 86 | 56 | 126 | Заглавная V |
| W | 87 | 57 | 127 | Заглавная W |
| X | 88 | 58 | 130 | Заглавная X |
| Y | 89 | 59 | 131 | Заглавная Y |
| Z | 90 | 5a | 132 | Заглавная Z |
| [ | 91 | 5b | 133 | Открывающая квадратная скобка |
| \ | 92 | 5c | 134 | Обратная наклонная черта (обратный слеш) |
| ] | 93 | 5d | 135 | Закрывающая квадратная скобка |
| ^ | 94 | 5e | 136 | Циркумфлекс, возведение в степень, знак вставки |
| _ | 95 | 5f | 137 | Нижнее подчёркивание |
| ` | 96 | 60 | 140 | Открывающая одиночная кавычка, гравис, знак ударения |
| a | 97 | 61 | 141 | Строчная a |
| b | 98 | 62 | 142 | Строчная b |
| c | 99 | 63 | 143 | Строчная c |
| d | 100 | 64 | 144 | Строчная d |
| e | 101 | 65 | 145 | Строчная e |
| f | 102 | 66 | 146 | Строчная f |
| g | 103 | 67 | 147 | Строчная g |
| h | 104 | 68 | 150 | Строчная h |
| i | 105 | 69 | 151 | Строчная i |
| j | 106 | 6a | 152 | Строчная j |
| k | 107 | 6b | 153 | Строчная k |
| l | 108 | 6c | 154 | Строчная l |
| m | 109 | 6d | 155 | Строчная m |
| n | 110 | 6e | 156 | Строчная n |
| o | 111 | 6f | 157 | Строчная o |
| p | 112 | 70 | 160 | Строчная p |
| q | 113 | 71 | 161 | Строчная q |
| r | 114 | 72 | 162 | Строчная r |
| s | 115 | 73 | 163 | Строчная s |
| t | 116 | 74 | 164 | Строчная t |
| u | 117 | 75 | 165 | Строчная u |
| v | 118 | 76 | 166 | Строчная v |
| w | 119 | 77 | 167 | Строчная w |
| x | 120 | 78 | 170 | Строчная x |
| y | 121 | 79 | 171 | Строчная y |
| z | 122 | 7a | 172 | Строчная z |
| < | 123 | 7b | 173 | Открывающая фигурная скобка |
| | | 124 | 7c | 174 | Вертикальная черта |
| > | 125 | 7d | 175 | Закрывающая фигурная скобка |
| 126 | 7e | 176 | Тильда (приблизительно) |
Расширенный набор символов (ANSI) в русской кодировке Win-1251
Этот день мы приближали, как могли — блокнот в Windows 10 стал понимать юниксовый перевод строки
Notepad в windows 10 начал понимать юниксовый перевод строки, а не только формат Windows.
С проблемой «каши» вместо удобочитаемого текста десятилетиями сталкивались те, кто пытался открыть в среде Windows текстовые документы, подготовленные на других операционных системах. Теперь же всё в одночасье изменяется. И это изменение столь же мало, сколь и эпично по своим практическим результатам и идеологическим последствиям. Microsoft вновь пытается играть в кросс-интеграцию и поддержку открытых стандартов.
Долгие годы Windows Блокнот мог нормально отображать только те текстовые документы, которые содержали символы начала новой строки в формате Windows End of Line (EOL) — «возврат каретки» (CR) и «подача на строку» (LF). На деле это приводило к тому, что Notepad не смог правильно отобразить содержимое текстовых файлов, созданных в Unix, Linux и macOS, где в качестве признака конца строки использовался только символ LF.

Обратите внимание, что строка состояния указывает обнаруженный формат EOL текущего открытого файла.
Так же для гибкого управления новой возможностью в разделе реестра [HKEY_CURRENT_USER\Software\Microsoft\Notepad] вводятся два дополнительных ключа:
По накалу страстей спор о способе начала новой строки в электронных документах сравним со спором о пробелах и табуляциях в исходных текстах программ. У этого противостояния «за строку» было много причин, как лежащих в области древних стандартов и традиций, так и берущих свои корни в особенностях конструкции печатных машин и телетайпов. Не меньшую роль сыграло и стремление одних программистов буквально выполнять (интерпретировать) команды и управляющие символы, а других — следовать здравому смыслу.
Что мы можем узнать о проблеме из Википедии
Исторически на механических пишущих машинках был рычаг, который возвращал каретку к левому краю страницы и прокручивал вал, подвигая бумагу вверх на строку. На телетайпах и более поздних алфавитно-цифровых печатающих устройствах (АЦПУ) вместо каретки была головка, в лазерных принтерах она перестала быть материальной, но в термине возврат каретки всё это продолжали называть кареткой, чтобы его не менять. На телетайпах возврат каретки и подачу строки разделили, откуда традиция представления перевода строки как CR+LF перешла и к текстовым файлам.
Системы, основанные на ASCII или совместимом наборе символов, используют или LF (перевод строки, 0x0A), или CR (возврат каретки, 0x0D) по отдельности, или последовательность CR+LF. Эти названия основаны на командах принтера: перевод строки означает, что одна строка на бумаге должна быть перенесена при печати, а возврат каретки означает, что каретка печатающего устройства должна вернуться к началу текущей строки.
Но как известно, стандарты стандартами, а реализации у всех часто выходят разными. И масла в огонь подливает необходимость корректно отображать унаследованные документы, созданные до эпохи юникода. Отсутствие единого общепринятого представления перевода строки в разных операционных системах надолго осложнило обмен текстовыми данными между ними.
Юникод старается примирить эту разницу, уравнивая CR, LF и CR+LF, однако вступает в противоречие с наследуемым им ASCII при трактовке последовательности LF+CR, не предварённой CR: согласно ASCII это один перевод строки, а согласно Юникоду — два.
HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
ASCII и шестнадцатеричное представление строк. Побитовые операции со строками
В литературе, которую я изучаю (например, по обратному инженерингу), для строк как само собой разумеющееся используются ASCII значения или запись в виде шестнадцатеричной строки. Подразумевается что читатели не только должны на лету конвертировать строки между обычным представлением, ASCII кодами символов, шестнадцатеричной и двоичной записью, но и должны уметь делать побитовые операции со строками.
На самом деле, это действительно не особенно сложная тема — достаточно один раз понять суть, а затем при необходимости можно пользоваться таблицами ASCII/Hex/Bin значений символов, либо конвертировать используя соответствующие утилиты или встроенные в языки программирования функции. Если у вас пробел в этих знаниях, то это статья должна вам помочь.
Смотрите также:
Для кого эта статья
Вам абсолютно точно нужно понимать суть ASCII кодирования символов, а также шестнадцатеричную запись строк если вы:
Примечание: правда, я исхожу из того, что вы знаете что такое:
По идее, это охватывается базовым курсом информатики и логики на любых специальностях в ВУЗе (некоторые учат это уже в школе) и это должен знать каждый — поэтому я не будут на этом останавливаться. Если вы не знаете даже этого, то прежде чем читать эту заметку, начните с ликвидации ваших более базовых пробелов про системы счисления.
Что такое ASCII
Не будем тратить время на экскурсы в историю о появлении ASCII — рассмотрим только с практической точки зрения.
А с практической точки зрения в ASCII каждому символу соответствует его порядковый номер. Этот порядковый номер можно записать десятичным числом, например, символу «h» соответствует 104, а символу «i» соответствует 105.
Любое десятичное число можно конвертировать в шестнадцатеричное, двоичное или восьмеричное число. Зачем конвертировать? Главная причина в том, что компьютер в своей основе не работает с десятеричными числами, а использует двоичные, которые удобно записывать в более компактном виде — конвертировать в шестнадцатеричные. Поэтому в определённых программах широко используются эти записи: в шестнадцатеричных редакторах, отладчиках. Также шестнадцатеричную/двоичную запись строк программист может использовать для различных манипуляций, например, с целью шифрования или другой обработки. Например, для тех же самых побитовых операций, к которым мы вернёмся позже.
Итак, вот таблицы символов, с их цифровым представлением в различных системах счисления:
Контрольные символы ASCII (некоторые из них больше не актуальны, так как подразумевают использование в телетайп связи)
Во многих языках программирования символ обозначается как «\n». Нажатие на клавишу ↵ Enter при выводе текста переводит строку.
В настоящее время символ вставляется нажатием комбинации клавиш Ctrl + Z и используется для обозначения конца файла в операционных системах «DOS» и «Windows».
Код этого символа происходит из первых текстовых процессоров с памятью на перфоленте: в них удаление символа происходило «забиванием» его кода дырочками (обозначавшими логические единицы).
Печатные символы ASCII
Расширенные символы ASCII
| Десятичное значение | Шестнадцатеричное | Двоичное | Символ | Описание |
|---|---|---|---|---|
| 128 | 80 | 10000000 | | |
| 129 | 81 | 10000001 | | |
| 130 | 82 | 10000010 | | |
| 131 | 83 | 10000011 | | |
| 132 | 84 | 10000100 | | |
| 133 | 85 | 10000101 | ||
| 134 | 86 | 10000110 | | |
| 135 | 87 | 10000111 | | |
| 136 | 88 | 10001000 | | |
| 137 | 89 | 10001001 | | |
| 138 | 8A | 10001010 | | |
| 139 | 8B | 10001011 | | |
| 140 | 8C | 10001100 | | |
| 141 | 8D | 10001101 | | |
| 142 | 8E | 10001110 | | |
| 143 | 8F | 10001111 | | |
| 144 | 90 | 10010000 | | |
| 145 | 91 | 10010001 | | |
| 146 | 92 | 10010010 | | |
| 147 | 93 | 10010011 | | |
| 148 | 94 | 10010100 | | |
| 149 | 95 | 10010101 | | |
| 150 | 96 | 10010110 | | |
| 151 | 97 | 10010111 | | |
| 152 | 98 | 10011000 | | |
| 153 | 99 | 10011001 | | |
| 154 | 9A | 10011010 | | |
| 155 | 9B | 10011011 | | |
| 156 | 9C | 10011100 | | |
| 157 | 9D | 10011101 | | |
| 158 | 9E | 10011110 | | |
| 159 | 9F | 10011111 | | |
| 160 | A0 | 10100000 | пробел | |
| 161 | A1 | 10100001 | ¡ | |
| 162 | A2 | 10100010 | ¢ | цент |
| 163 | A3 | 10100011 | £ | фунт |
| 164 | A4 | 10100100 | ¤ | знак валюты |
| 165 | A5 | 10100101 | ¥ | иена, юань |
| 166 | A6 | 10100110 | ¦ | сломанный бар |
| 167 | A7 | 10100111 | § | знак параграфа |
| 168 | A8 | 10101000 | ¨ | |
| 169 | A9 | 10101001 | © | копирайт |
| 170 | AA | 10101010 | ª | порядковый индикатор |
| 171 | AB | 10101011 | « | |
| 172 | AC | 10101100 | ¬ | |
| 173 | AD | 10101101 | ||
| 174 | AE | 10101110 | ® | зарегистрированная торговая марка |
| 175 | AF | 10101111 | ¯ | |
| 176 | B0 | 10110000 | ° | градус |
| 177 | B1 | 10110001 | ± | плюс-минус |
| 178 | B2 | 10110010 | ² | |
| 179 | B3 | 10110011 | ³ | |
| 180 | B4 | 10110100 | ´ | |
| 181 | B5 | 10110101 | µ | мю |
| 182 | B6 | 10110110 | ¶ | знак абзаца |
| 183 | B7 | 10110111 | · | |
| 184 | B8 | 10111000 | ¸ | |
| 185 | B9 | 10111001 | ¹ | |
| 186 | BA | 10111010 | º | порядковый индикатор |
| 187 | BB | 10111011 | » | |
| 188 | BC | 10111100 | ¼ | |
| 189 | BD | 10111101 | ½ | |
| 190 | BE | 10111110 | ¾ | |
| 191 | BF | 10111111 | ¿ | перевернутый знак вопроса |
| 192 | C0 | 11000000 | À | |
| 193 | C1 | 11000001 | Á | |
| 194 | C2 | 11000010 | Â | |
| 195 | C3 | 11000011 | Ã | |
| 196 | C4 | 11000100 | Ä | |
| 197 | C5 | 11000101 | Å | |
| 198 | C6 | 11000110 | Æ | |
| 199 | C7 | 11000111 | Ç | |
| 200 | C8 | 11001000 | È | |
| 201 | C9 | 11001001 | É | |
| 202 | CA | 11001010 | Ê | |
| 203 | CB | 11001011 | Ë | |
| 204 | CC | 11001100 | Ì | |
| 205 | CD | 11001101 | Í | |
| 206 | CE | 11001110 | Î | |
| 207 | CF | 11001111 | Ï | |
| 208 | D0 | 11010000 | Ð | |
| 209 | D1 | 11010001 | Ñ | |
| 210 | D2 | 11010010 | Ò | |
| 211 | D3 | 11010011 | Ó | |
| 212 | D4 | 11010100 | Ô | |
| 213 | D5 | 11010101 | Õ | |
| 214 | D6 | 11010110 | Ö | |
| 215 | D7 | 11010111 | × | знак умножения |
| 216 | D8 | 11011000 | Ø | |
| 217 | D9 | 11011001 | Ù | |
| 218 | DA | 11011010 | Ú | |
| 219 | DB | 11011011 | Û | |
| 220 | DC | 11011100 | Ü | |
| 221 | DD | 11011101 | Ý | |
| 222 | DE | 11011110 | Þ | |
| 223 | DF | 11011111 | ß | |
| 224 | E0 | 11100000 | à | |
| 225 | E1 | 11100001 | á | |
| 226 | E2 | 11100010 | â | |
| 227 | E3 | 11100011 | ã | |
| 228 | E4 | 11100100 | ä | |
| 229 | E5 | 11100101 | å | |
| 230 | E6 | 11100110 | æ | |
| 231 | E7 | 11100111 | ç | |
| 232 | E8 | 11101000 | è | |
| 233 | E9 | 11101001 | é | |
| 234 | EA | 11101010 | ê | |
| 235 | EB | 11101011 | ë | |
| 236 | EC | 11101100 | ì | |
| 237 | ED | 11101101 | í | |
| 238 | EE | 11101110 | î | |
| 239 | EF | 11101111 | ï | |
| 240 | F0 | 11110000 | ð | |
| 241 | F1 | 11110001 | ñ | |
| 242 | F2 | 11110010 | ò | |
| 243 | F3 | 11110011 | ó | |
| 244 | F4 | 11110100 | ô | |
| 245 | F5 | 11110101 | õ | |
| 246 | F6 | 11110110 | ö | |
| 247 | F7 | 11110111 | ÷ | крестик |
| 248 | F8 | 11111000 | ø | |
| 249 | F9 | 11111001 | ù | |
| 250 | FA | 11111010 | ú | |
| 251 | FB | 11111011 | û | |
| 252 | FC | 11111100 | ü | |
| 253 | FD | 11111101 | ý | |
| 254 | FE | 11111110 | þ | |
| 255 | FF | 11111111 | ÿ |
Как отличить двоичное, шестнадцатеричное и десятичное написание друг от друга
Конкретные нотации могут различаться в зависимости от языка программирования или используемой программы (printf, printf, xxd, hexdump и так далее), но обычно используются следующие правила:
По умолчанию целочисленный литерал (число) — это десятичное целое число.
Для обозначения двоичного целочисленного литерала перед ним используется 0b или 0B (ноль B). Иногда буква b ставится позади числа.
Для обозначения восьмеричного целочисленного литерала, перед ним используется 0 (ноль).
А для обозначения шестнадцатеричного целочисленного литерала, перед ним используется 0x или 0X (ноль X).
В Radare2 можно увидеть такую запись:
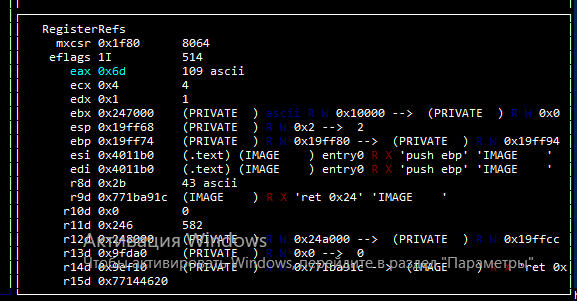
Обратите внимание на переменную eax, значение которой равно 0x6d, а затем дано пояснение 109 ascii. То есть в шестнадцатеричном виде значение переменной eax равно 0x6d, в десятеричном это 109 что соответствует символу m.
ASCII и HTML
Если в HTML коде перед десятичным кодом ASCII символа поставить &#, то веб-браузер отобразит этот символ.
К примеру, если использовать ', то веб-браузер покажет ‘ (одинарную кавычку). Некоторые преобразователи строк внутри веб-приложения также могут конвертировать написание символов &#XX в их ASCII представления. Поэтому безобидная запись ' внутри веб-приложения может превратиться в одинарную кавычку, которая может нарушить SQL запрос.
Аналогично можно использовать &#x, после которой нужно указать код символа в шестнадцатеричной системе, например, ' также покажет кавычку. Для разделения символов друг от друга, используйте точку с запятой, например, ‘hi’
Многие программы понимают шестнадцатеричную запись, правда вид записи может различаться от конкретной программы и языка программирования.
В JavaScript шестнадцатеричные строки записываются в виде экранированной последовательности:
Можно записать код символов в восьмеричной системе счисления:
Аналогично Bash понимает такие строки:
И PHP их обрабатывает верно:
Побитовые операции над строками
К побитовым операторам относятся:
Если вспомнить школьный/ВУЗовский курс логики, то там такие операции выполняются с нулями и единицами. То есть их можно выполнить с бинарными данными, например, с двоичными числами.
В языках программирования можно делать побитовые операции с десятичными числами, например Побитовое ИСКЛЮЧАЮЩЕЕ ИЛИ (XOR) в PHP:
Дело в том, что числа будут автоматически переведены в двоичный вид и операция будет выполнена уже над двоичными числами.
8 и 5 в двоичном виде это соответственно 1000 и 101, можно также из записать так: 1000 и 0101.
Получаем конечное число: 1101
То есть в PHP операция проделана правильно, даже не смотря на то, что мы указали не двоичные числа, а десятичные.
Когда говорят о побитовых операциях со строками, то имеют в виду, что используется ASCII код символа (который затем переводиться в двоичный вид). После выполнения требуемой операции, выполняется обратное преобразование — число переводиться в ASCII символ.
Кстати, про ИСКЛЮЧАЮЩЕЕ ИЛИ (XOR) — у этой операции есть интересное свойство:
То есть можно взять строки и выполнить между ними операцию XOR. В результате получиться бессмысленный набор символов. Затем если между этой бессмысленной строкой и любой из первоначальных строк вновь выполнить операцию XOR, то получиться вторая начальная строка.
На этом основано простейшее симметричное шифрование: исходный текст шифруется паролем с помощью XOR. То есть с первым символом текста и первыми символом пароля делается операция XOR, затем со вторым символом шифруемого текста и вторым символом пароля делается операция XOR и так далее, пока шифруемый текст не кончится. Поскольку пароль обычно короче шифруемого текста, то когда он заканчивается, вновь выполняется переход к первому символу пароля и так далее много раз.
В результате получается бессмысленный набор символов, которые можно расшифровать этим же паролем выполняя эту же операцию XOR.
Правда, зашифрованные таким образом тексты часто приводятся для тренировки в литературе по взлому шифров: если текст достаточно длинный, то с помощью статистического анализа того, как часто в нём встречаются символы и сравнивая эту частотность с естественной частотностью букв в языке, сначала вычисляют длину пароля, а затем и сам пароль. То есть это крайне ненадёжный шифр.
Вычитание числа из строки и прибавление к строкам числа
В статье «Анализ вредоносной программы под Linux: плохое самодельное шифрование» рассматривается шифрование, которое основано на прибавлении или вычитании числа к символу строки (на основе позиции символов). Как я думаю вы уже поняли, используется аналогичный приём: берётся ASCII код символа и из этого числа делается вычитание или находиться сумма с ним, а затем полученное число опять переводят в ASCII символ.
Побитовые операции с цифрами: нужно переводить в двоичную систему сами цифры или брать двоичные значения ASCII каждого символа?
Допустим, мы хотим сделать побитовую операцию 5 OR 7. Какой будет результат? Микропроцессор не работает ни с числами в десятичной системе, ни с ASCII строками — микропроцессор работает только двоичными числами.
То есть возникает вопрос:
2. Это ASCII строки?
Рассмотрим оба эти варианта, чтобы понять, насколько они различаются.
Число 5 в двоичной системе это 101, а число 7 в двоичной системе это 111.
В результате выполнения
Будет получено 111. То есть результатом данной операции является число 7.
5 и 7 — это ASCII строки
Смотрим таблицу ASCII символов, там цифре 5 соответствует код 00110101, а цифре 7 соответствует код 00110111. Делаем побитовую операцию OR между ними:
00110101 OR 00110111
Получаем: 110111, что в таблице ASCII символов также соответствует символу «7».
Итак, в принципе, можно напрямую переводить данные цифры в их двоичные значения, либо можно использовать двоичные значения их символов. Самое главное, придерживаться одной и той же схемы и преобразовывать с учётом выбранного пути. Ведь если вы делаете логическую операцию (например OR), с ASCII значением, а затем начинаете толковать полученный результат как число, то такое число (в нашем примере), будет равно 110111 = 55 (в десятичной системе). Или наоборот, вы сделали побитовую операцию между 101 OR 111, а затем полученный результат 111 начинаете трактовать как ASCII код символа — то тогда вместо числа вы получите управляющий символ «звуковой сигнал: звонок».
Заключение
Подытожим: у всех символов (печатных и непечатных) есть свой код ASCII. Кстати, ASCII — это ведь одна из многих кодировок. Существует много разных кодировок, например, очень популярна UTF8 и там у символов свои собственные коды. Причём используя экранированные последовательности можно записывать символы UTF8 по аналогии, как это показано с ASCII.
О том, как разными способами записать один и тот же символ (на примере “>”) смотрите здесь: https://security.stackexchange.com/questions/205967/character-escape-sequences-for
Эти техники могут использоваться в обходе фильтрации символов и слов.



