Установка SQLAlchemy и подключение к базе данных
SQLAlchemy можно использовать с Python 2.7 и более поздними версиями. В этом руководстве будет использоваться Python 3.8, но вы можете выбрать любую версию Python 3.6+.
Установка SQLAlchemy
Для установки SQLAlchemy введите следующее:
Чтобы проверить успешность установки введите следующее в командной строке:
Установка DBAPI
По умолчанию SQLAlchemy работает только с базой данных SQLite без дополнительных драйверов. Для работы с другими базами данных необходимо установить DBAPI-совместимый драйвер в соответствии с базой данных.
Что такое DBAPI?
DBAPI — это стандарт, который поощряет один и тот же API для работы с большим количеством баз данных. В следующей таблице перечислены все DBAPI-совместимые драйверы:
| База данных | DBAPI драйвер |
|---|---|
| MySQL | PyMySQL, MySQL-Connector, CyMySQL, MySQL-Python (по умолчанию) |
| PostgreSQL | psycopg2 (по умолчанию), pg8000, |
| Microsoft SQL Server | PyODBC (по умолчанию), pymssql |
| Oracle | cx-Oracle (по умолчанию) |
| Firebird | fdb (по умолчанию), kinterbasdb |
Все примеры в этом руководстве протестированы в PostgreSQL, но вы можете выбрать базу данных по вкусу. Для установки DBAPI psycopg2 для PostgreSQL введите следующую команду:
Подготовка к подключению
Диалект SQLAlchemy
А вот как получить тот же результат для MySQL:
Чтобы обрабатывать эти различия нужен диалект. Диалект определяет поведение базы данных. Другими словами он отвечает за обработку SQL-инструкций, выполнение, обработку результатов и так далее. После установки соответствующего драйвера диалект обрабатывает все отличия, что позволяет сосредоточиться на создании самого приложения.
Пул соединений SQLAlchemy
Пул соединений — это стандартный способ кэширования соединений в памяти, что позволяет использовать их повторно. Создавать соединение каждый раз при необходимости связаться с базой данных — затратно. А пул соединений обеспечивает неплохой прирост производительности.
При таком подходе приложение при необходимости обратиться к базе данных вытягивает соединение из пула. После выполнения запросов подключение освобождается и возвращается в пул. Новое создается только в том случае, если все остальные связаны.
Вот код для создания движка некоторых популярных баз данных:
Руководство по SQLAlchemy в Flask
Для работы понадобится python 3.6+, библиотеки SQLAlchemy и Flask. Код урока здесь.
Версии библиотек в файле requirements.txt
В этом материале речь пойдет об основах SQLAlchemy. Создадим веб-приложение на Flask, фреймворке языка Python. Это будет минималистичное приложение, которое ведет учет книг.
С его помощью можно будет добавлять новые книги, читать уже существующие, обновлять и удалять их. Эти операции — создание, чтение, обновление и удаление — также известны как «CRUD» и составляют основу почти всех веб-приложений. О них отдельно пойдет речь в статье.
Но прежде чем переходить к CRUD, разберемся с отдельными элементами приложения, начиная с SQLAlchemy.
Что такое SQLAlchemy?
Как написано на сайте библиотеки «SQLAlchemy — это набор SQL-инструментов для Python и инструмент объектно-реляционного отображения (ORM), который предоставляет разработчикам всю мощь и гибкость SQL».
При чтении этого определения в первую очередь возникает вопрос: а что же такое объектно-реляционное отображение? ORM — это техника, используемая для написания запросов к базам данных с помощью парадигм объектно-ориентированного программирования выбранного языка (Python в этом случае).
Если еще проще, ORM — это своеобразный переводчик, который переводит код с одного набора абстракций в другой. В этом случае — из Python в SQL.
Есть масса причин, почему стоит использовать ORM, а не вручную сооружать строки SQL. Вот некоторые из них:
Углубимся еще сильнее.
Зачем использовать ORM, когда можно писать сырой SQL? При написании запросов на сыром SQL, мы передаем их базе данных в виде строк. Следующий запрос написан на сыром SQL:
Нет ничего плохого в использовании чистого SQL для обращения к базам данных, только если вы не сделаете ошибку в запросе. Это может быть, например, опечатка в названии базы, к которой происходит обращение или неправильное название таблицы. Компилятор Python здесь ничем не поможет.
SQLAlchemy — один из множества ORM-инструментов для Python. При работе с маленькими приложения чистый SQL может сработать. Но если это большой сайт с массой данных, такой подход сильнее подвержен ошибкам и просто более сложен.
Создание базы данных с помощью SQLAlchemy
Согласно документации declarative_base() возвращает новый базовый класс, который наследуют все связанные классы. Это таблица, mapper() и объекты класса в пределах его определения.
После настройки базы данных создаем классы. В SQLAlchemy классы являются объектно-ориентированными или декларативными представлениями таблицы в базе данных.
Есть много атрибутов класса, которые используются для определения колонок, но рассмотрим уже использованные:
CRUD с SQLAlchemy на примерах
В начале кратко была затронута тема операций CRUD. Пришло время их использовать.
Создадим еще один файл и назовем его populate.py (или любым другим именем).
CREATE:
Стандартный процесс создания записи следующий:
Создать первую книгу можно с помощью следующей команды:
В зависимости от того, что нужно прочитать, используются разные функции. Рассмотрим два варианты их использования в приложении.
session.query(Book).all() — вернет список всех книг
UPDATE:
Для обновления записей в базе данных, нужно проделать следующее:
Если еще не заметили, в записи bookOne есть ошибка. Книгу «Чистый Python» написал Дэн Бейдер, а не «Дэн Бейде». Обновим имя автора с помощью 4 описанных шагов.
Чтобы сбросить и зафиксировать имя автора, нужны следующие команды:
DELETE:
Удаление значений из базы данных — это почти то же самое, что и обновление:
Теперь когда база данных настроена и есть базовое понимание CRUD-операций, пришло время написать небольшое приложение Flask. Но в сам фреймворк не будем углубляться. О нем можно подробнее почитать в других материалах.
Если запустить приложение app.py и перейти в браузере на страницу https://localhost:4996/books, отобразится список книг. Добавьте несколько и если все работает, это выглядит вот так:

Расширение приложения и выводы
Если вы добрались до этого момента, то теперь знаете чуть больше о том, как работает SQLAlchemy. Это важная и объемная тема, а в этом материале речь шла только об основных вещах, поэтому поработайте с другими CRUD-операциями и добавьте в приложение новые функции.
Можете добавить таблицу Shelf в базу данных, чтобы отслеживать свой прогресс чтения, или даже реализовать аутентификацию с авторизацией. Это сделает приложение более масштабируемым, а также позволит другим пользователям добавлять собственные книги.
Страница
Пользователь
Введение в SQLAlchemy
SQLAlchemy — это программное обеспечение с открытым исходным кодом для работы с базами данных при помощи языка SQL. Оно реализует технологию программирования ORM (Object-Relational Mapping), которая связывает базы данных с концепциями объектно-ориентированных языков программирования. SQLAlchemy позволяет описывать структуры баз данных и способы взаимодействия с ними прямо на языке Python. SQLAlchemy Реализована в виде пакета для Python под лицензией MIT, а значит возможно использование ее проприетарном ПО. SQLAlchemy была выпущена в феврале 2006 и быстро стала одним из самых распространенных инструментов ORM среди разработчиков на Python. SQLAlchemy обладает несколькими областями применения, которые могут использоваться как вместе, так и по отдельности. Его основные компоненты приведены ниже.
Установка SQLAlchemy
Вы можете установить SQLAlchemy с нуля, используя pip. Если он установлен, то вы можете просто набрать в консоли:
Эта команда скачает последнюю версию SQLAlchemy из Python Cheese Shop и установит ее на вашу машину.
Также можно просто скачать архив с SQLAlchemy с официального сайта и выполнить установочный скрипт setup.py
Для обновления уже установленной SQLAlchemy наберите в консоли:
Для проверки правильности установки следует проверить версию библиотеки:
Объектно-реляционная модель SQLAlchemy
Соединение с базой данных
В этом уроке мы будем использовать только БД SQLite, хранящуюся в памяти. Чтобы соединиться с СУБД, мы используем функцию create_engine():
Флаг echo включает ведение лога через стандартный модуль logging Питона. Когда он включен, мы увидим все созданные нами SQL-запросы. Если вы хотите просто пробежать этот урок и убрать отладочный вывод, то просто уберите его, поставив
По умолчанию соединение с БД через 8 часов простоя обрывается. Чтобы это не случилось нужно добавить опцию
и тогда каждые два часа соединение будет переустанавливаться.
Соединение с базой данных
Далее мы пожелаем рассказать SQLAlchemy о наших таблицах. Мы начнем с одиночной таблицы users, в которой будем хранить записи о наших конечных пользователях, которые посещают некий сайт N. Мы определим нашу таблицу внутри каталога MetaData, используя конструктор Table(), который похож на SQLный CREATE TABLE:
Все о том, как определять объекты Table и о том, как загружать их определение из существующей БД (рефлексия) рассмотрено в главе Метаданные БД. Далее же мы пошлем базе CREATE TABLE, параметры которого будут взяты из метаданных нашей таблицы. Мы вызовем метод create_all() и передадим ему наш объект engine, который и указывает на базу. Там сначала будет проверено присутствие такой таблицы перед ее созданием, так что можно выполнять это много раз — ничего страшного не случится.
Те, кто знаком с синтаксисом SQL и в частности CREATE TABLE, могут заметить, что колонки VARCHAR создаются без указания их длины. В SQLite это вполне допустимый тип данных, но во многих других СУБД так делать нельзя. Для того, чтобы выполнить этот урок в PostgreSQL или MySQL, длина должна быть передана строкам, как здесь:
Поле «длина» в строках String, как и простая разрядность/точность в Integer, Numeric и т. п. не используются более нигде, кроме как при создании таблиц.
Определение класса Python для отображения в таблицу
В то время, как класс Table хранит информацию о нашей БД, он ничего не говорит о логике объектов, что используются нашим приложением. SQLAlchemy считает это отдельным вопросом. Для соответствия нашей таблице users создадим элементарный класс User. Нужно только унаследоваться от базового питоньего класса Object (то есть у нас совершенно новый класс).
__init__ — это конструктор, __repr__ же вызывается при операторе print. Они определены здесь для удобства. Они не обязательны и могут иметь любую форму. SQLAlchemy не вызывает __init__ напрямую
Настройка отображения
Теперь мы хотим слить в едином порыве нашу таблицу user_table и класс User. Здесь нам пригодится пакет SQLAlchemy ORM. Мы применим функцию mapper, чтобы создать отображение между user_table и User.
Функция mapper() создаст новый Mapper-объект и сохранит его для дальнейшего применения, ассоциирующегося с нашим классом. Теперь создадим и проверим объект типа User:
Атрибут id, который не определен в __init__, все равно существует из-за того, что колонка id существует в объекте таблицы users_table. Стандартно mapper() создает атрибуты класса для всех колонок, что есть в Table. Эти атрибуты существуют как питоньи дескрипторы и определяют его функциональность. Она может быть очень богатой и включать себе возможность отслеживать изменения и АВТОМАТИЧЕСКИ подгружать данные в базу, когда это необходимо. Так как мы не сказали SQLAlchemy сохранить Василия в базу, его id выставлено на None. Когда позже мы сохраним его, в этом атрибуте будет храниться некое автоматически сформированное значение.
Декларативное создание таблицы, класса и отображения за один раз.
Предыдущее приближение к конфигурированию, включающее таблицу Table, пользовательский класс и вызов mapper() иллюстрируют классический пример использования SQLAlchemy, в которой очень ценится разделение задач. Большое число приложений, однако, не требуют такого разделения, и для них SQLAlchemy предоставляет альтернативный, более лаконичный стиль: декларативный.
Имющиеся метаданные MetaData также доступны:
Еще один «декларативный» метод для SQLAlchemy доступен в сторонней библиотеке Elixir. Это полнофункциональный продукт, который включает много встроенных конфигураций высокоуровневого отображения. Как и деклaративы, как только классы и отображения определены, использование ORM будет таким же, как и в классическом SQLAlchemy.
Создание сессии
Теперь мы готовы начать наше общение с базой данных. «Ручка» базы в нашем случае – это сессия Session. Когда сначала мы запускаем приложение, на том же уровне нашего create_engine() мы определяем класс Session, что служит фабрикой объектов сессий (Session).
В случае же, если наше приложение не имеет Engine-объекта базы данных, можно просто сделать так:
А потом, когда вы создадите подключение к базе с помощью create_engine(), соедините его с сессией, используя configure():
Такой класс Session будет создавать Session-объекты, которые привязаны к нашей базе. Другие транзакционные параметры тоже можно определить вызовом sessionmaker()’а, но они будут описаны в следующей главе. Так, когда вам необходимо общение с базой, вы создаете объект класса Session:
Сессия здесь ассоциирована с SQLite, но у нее еще нет открытых соединений с этой базой. При первом использовании она получает соединение из набора соединений, который поддерживается engine и удерживает его до тех пор, пока мы не применим все изменения и/или не закроем объект сессии.
Добавление новых объектов
Чтобы сохранить наш User-объект, нужно добавить его к нашей сессии, вызвав add():
Этот объект будет находиться в ожидании сохранения, никакого SQL-запроса пока послано не будет. Сессия пошлет SQL-запрос, чтобы сохранить Васю, как только это понадобитья, используя процесс сброса на диск(flush). Если мы запросим Васю из базы, то сначала вся ожидающая информация будет сброшена в базу, а запрос последует потом. Для примера, ниже мы создадим новый объект запроса (Query), который загружает User-объекты. Мы «отфильтровываем» по атрибуту «имя=Вася» и говорим, что нам нужен только первый результат из всего списка строк. Возвращается тот User, который равен добавленному:
На самом деле сессия определила, что та запись из таблицы, что она вернула, та же самая, что а запись, что она уже представляла в своей внутренней хеш-таблицу объектов. Так что мы просто получили точно тот же самые объект, что только что добавили. Та концепция ORM, что работает здесь, известная как карта идентичности, обеспечивает, что все операции над конкретной записью внутри сессии оперируют одним и тем же набором данных. Как только объект с неким первичным ключом появится в сессии, все SQL-запросы на этой сессии вернут тот же самые питоний объект для этого самого первичного ключа. Будет выдана ошибка в случае попытки поместить в эту сессию другой, уже сохраненный объект с тем же первичным ключом. Мы можем добавить больше User-объектов, использовав add_all()
А вот тут Вася решил, что его старый пароль слишком простой, так что давайте его сменим:
Сессия внимательно следит за нами. Она, для примера, знает, что Вася был модифицирован:
И что еще пара User’ов ожидают сброса в базу:
А теперь мы скажем нашей сессии, что мы хотим отправить все оставшиеся изменения в базу и применить все изменения, зафиксировав транзакцию, которая до того была в процессе. Это делается с помощью commit():
commit() сбрасывает все оставшиеся изменеия в базу и фиксирует транзакции. Ресурсы подключений, что использовались в сессии, снова освобождаются и возвращаются в набор. Последовательные операции с сессией произойдут в новой транзакции, которая снова запросит себе ресурсов по первому требованию. Если посмотреть васин атрибут id, что раньше был None, то мы увидим, что ему присвоено значение:
После того, как сессия вставит новые записи в базу, все только что созданные идентификаторы … будут доступны в объекте, немедленно или по первому требованию. В нашем случае, целая запись была перезагружена при доступе, как как после вызова commit() началась новая транзакция. SQLAlchemy стандартно обновляет данные от предыдущей транзакции при первом обращении с новой транзакцией, так что нам доступно самое последнее ее состояние. Уровень подгрузки настраивается, как описано в главе «Сессии».
Перевод: Головизин Алексей
Документации/SQLAlchemy (последним исправлял пользователь crenergo 2010-07-12 11:08:36)
SQLAlchemy 1.4 Documentation
SQLAlchemy 1.4 Documentation
SQLAlchemy 1.4 Documentation
Project Versions
Overview¶
The SQLAlchemy SQL Toolkit and Object Relational Mapper is a comprehensive set of tools for working with databases and Python. It has several distinct areas of functionality which can be used individually or combined together. Its major components are illustrated below, with component dependencies organized into layers:
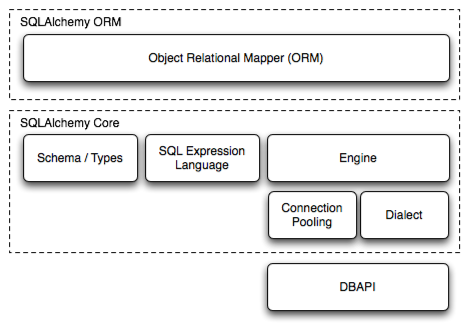
Above, the two most significant front-facing portions of SQLAlchemy are the Object Relational Mapper (ORM) and the Core.
Core contains the breadth of SQLAlchemy’s SQL and database integration and description services, the most prominent part of this being the SQL Expression Language.
The SQL Expression Language is a toolkit all its own, independent of the ORM package, which provides a system of constructing SQL expressions represented by composable objects, which can then be “executed” against a target database within the scope of a specific transaction, returning a result set. Inserts, updates and deletes (i.e. DML ) are achieved by passing SQL expression objects representing these statements along with dictionaries that represent parameters to be used with each statement.
Whereas working with Core and the SQL Expression language presents a schema-centric view of the database, along with a programming paradigm that is oriented around immutability, the ORM builds on top of this a domain-centric view of the database with a programming paradigm that is more explcitly object-oriented and reliant upon mutability. Since a relational database is itself a mutable service, the difference is that Core/SQL Expression language is command oriented whereas the ORM is state oriented.
Documentation Overview¶
The documentation is separated into four sections:
Code Examples¶
There is also a wide variety of examples involving both core SQLAlchemy constructs as well as the ORM on the wiki. See Theatrum Chemicum.
Installation Guide¶
Supported Platforms¶
SQLAlchemy has been tested against the following platforms:
cPython 3.6 and higher
Changed in version 1.4: Within the Python 3 series, 3.6 is now the minimum Python 3 version supported.
AsyncIO Support¶
SQLAlchemy’s asyncio support depends upon the greenlet project. This dependency will be installed by default on common machine platforms, however is not supported on every architecture and also may not install by default on less common architectures. See the section Asyncio Platform Installation Notes for additional details on ensuring asyncio support is present.
Supported Installation Methods¶
SQLAlchemy installation is via standard Python methodologies that are based on setuptools, either by referring to setup.py directly or by using pip or other setuptools-compatible approaches.
Changed in version 1.1: setuptools is now required by the setup.py file; plain distutils installs are no longer supported.
Install via pip¶
When pip is available, the distribution can be downloaded from PyPI and installed in one step:
This command will download the latest released version of SQLAlchemy from the Python Cheese Shop and install it to your system.
Where above, if the most recent version is a prerelease, it will be installed instead of the latest released version.
Installing using setup.py¶
Otherwise, you can install from the distribution using the setup.py script:
Installing the C Extensions¶
SQLAlchemy includes C extensions which provide an extra speed boost for dealing with result sets. The extensions are supported on both the 2.xx and 3.xx series of cPython.
setup.py will automatically build the extensions if an appropriate platform is detected. If the build of the C extensions fails due to a missing compiler or other issue, the setup process will output a warning message and re-run the build without the C extensions upon completion, reporting final status.
To run the build/install without even attempting to compile the C extensions, the DISABLE_SQLALCHEMY_CEXT environment variable may be specified. The use case for this is either for special testing circumstances, or in the rare case of compatibility/build issues not overcome by the usual “rebuild” mechanism:
Installing a Database API¶
SQLAlchemy is designed to operate with a DBAPI implementation built for a particular database, and includes support for the most popular databases. The individual database sections in Dialects enumerate the available DBAPIs for each database, including external links.
Checking the Installed SQLAlchemy Version¶
This documentation covers SQLAlchemy version 1.4. If you’re working on a system that already has SQLAlchemy installed, check the version from your Python prompt like this:
1.3 to 1.4 Migration¶
flambé! the dragon and The Alchemist image designs created and generously donated by Rotem Yaari.
SQLAlchemy
Содержание
Введение в SQLAlchemy [ править ]
SQLAlchemy — это программное обеспечение с открытым исходным кодом для работы с базами данных при помощи языка SQL. Оно реализует технологию программирования ORM (Object-Relational Mapping), которая связывает базы данных с концепциями объектно-ориентированных языков программирования. SQLAlchemy позволяет описывать структуры баз данных и способы взаимодействия с ними прямо на языке Python. SQLAlchemy реализована в виде пакета для Python под лицензией MIT, а значит возможно ее использование в проприетарном ПО.
SQLAlchemy была выпущена в феврале 2006 и быстро стала одним из самых распространенных инструментов ORM среди разработчиков на Python. SQLAlchemy обладает несколькими областями применения, которые могут использоваться как вместе, так и по отдельности. Его основные компоненты приведены ниже.

Здесь будут представлены несколько уроков по использованию этого замечательного фреймворка.
Установка SQLAlchemy [ править ]
Вы можете установить SQLAlchemy с нуля, используя setuptools. Если они установлены, то вы можете просто набрать в консоли:
Эта команда скачает последнюю версию SQLAlchemy из Python Cheese Shop и установит ее на вашу машину.
Также можно просто и без затей скачать архив с SQLAlchemy c официального сайта и выполнить установочный скрипт setup.py:
Установка с помощью pip:
Для проверки правильности установки следует проверить версию библиотеки:
Объектно-реляционная модель SQLAlchemy [ править ]
Соединение с базой данных [ править ]
В этом уроке мы будем использовать только БД SQLite, хранящуюся в памяти. Чтобы соединиться с СУБД, мы используем функцию create_engine():
Флаг echo включает ведение лога через стандартный модуль logging Питона.
Когда он включен, мы увидим все созданные нами SQL-запросы. Если вы хотите просто пробежать этот урок и убрать отладочный вывод, то просто уберите его, поставив
Создание таблицы в базе данных [ править ]
Далее мы хотим рассказать SQLAlchemy о наших таблицах. Мы начнем с одиночной таблицы users, В которой будем хранить записи о наших конечных пользователях, которые посещают некий сайт N. Мы определим нашу таблицу внутри каталога MetaData, используя конструктор Table(), который похож на SQLный CREATE TABLE:
Все о том, как определять объекты Table и о том, как загружать их определение из существующей БД (рефлексия) рассмотрено в главе Метаданные БД.
Далее же мы пошлем базе команду CREATE TABLE, параметры которой будут взяты из метаданных нашей таблицы. Мы вызовем метод create_all() и передадим ему наш объект engine, который и указывает на базу. Там сначала будет проверено присутствие такой таблицы перед ее созданием, так что можно выполнять это много раз — ничего страшного не случится.
Те, кто знаком с синтаксисом SQL и в частности CREATE TABLE, могут заметить, что колонки VARCHAR создаются без указания их длины. В SQLite и PostgreSQL это вполне допустимый тип данных, но во многих других СУБД так делать нельзя. Для того, чтобы выполнить этот урок в MySQL, длина должна быть передана строкам, как здесь:
Поле «длина» в строках String, как и простая разрядность/точность в Integer, Numeric и т. п. не используются более нигде, кроме как при создании таблиц.
Определение класса Python для отображения в таблицу [ править ]
В то время, как класс Table хранит информацию о нашей БД, он ничего не говорит о логике объектов, что используются нашим приложением. SQLAlchemy считает это отдельным вопросом. Для соответствия нашей таблице users создадим элементарный класс User. Нужно только унаследоваться от базового питоньего класса Object (то есть у нас совершенно новый класс).
__init__ — это конструктор, __repr__ же вызывается при операторе print. Они определены здесь для удобства. Они не обязательны и могут иметь любую форму. SQLAlchemy не вызывает __init__ напрямую
Настройка отображения [ править ]
Теперь мы хотим слить в едином порыве нашу таблицу user_table и класс User. Здесь нам пригодится пакет SQLAlchemy ORM. Мы применим функцию mapper, чтобы создать отображение между users_table и User.
Функция mapper() создаст новый Mapper-объект и сохранит его для дальнейшего применения, ассоциирующегося с нашим классом. Теперь создадим и проверим объект типа User:
Атрибут id, который не определен в __init__, все равно существует из-за того, что колонка id существует в объекте таблицы users_table. Стандартно mapper() создает атрибуты класса для всех колонок, что есть в Table. Эти атрибуты существуют как Python дескрипторы и определяют его функциональность. Она может быть очень богатой и включать в себе возможность отслеживать изменения и АВТОМАТИЧЕСКИ подгружать данные в базу, когда это необходимо. Так как мы не сказали SQLAlchemy сохранить Василия в базу, его id выставлено на None. Когда позже мы сохраним его, в этом атрибуте будет храниться некое автоматически сформированное значение.
Декларативное создание таблицы, класса и отображения за один раз [ править ]
Предыдущый подход к конфигурированию, включающий таблицу Table, пользовательский класс и вызов mapper() иллюстрируют классический пример использования SQLAlchemy, в которой очень ценится разделение задач. Большое число приложений, однако, не требуют такого разделения, и для них SQLAlchemy предоставляет альтернативный, более лаконичный стиль: декларативный.
Выше — функция declarative_base(), что определяет новый класс, который мы назвали Base, от которого будет унаследованы все наши ORM-классы. Обратите внимание: мы определили объекты Column безо всякой строки имени, так как она будет выведена из имени своего атрибута. Низлежащий объект Table, что создан нашей declarative_base() версией User, доступен через атрибут __table__
Имющиеся метаданные MetaData также доступны:
Еще один «декларативный» метод для SQLAlchemy доступен в сторонней библиотеке Elixir. Это полнофункциональный продукт, который включает много встроенных конфигураций высокоуровневого отображения. Как и деклaративы, как только классы и отображения определены, использование ORM будет таким же, как и в классическом SQLAlchemy.
Создание сессии [ править ]
Теперь мы готовы начать наше общение с базой данных. «Ручка» базы в нашем случае — это сессия Session. Когда сначала мы запускаем приложение, на том же уровне нашего create_engine() мы определяем класс Session, что служит фабрикой объектов сессий (Session).
В случае же, если наше приложение не имеет Engine-объекта базы данных, можно просто сделать так:
А потом, когда вы создадите подключение к базе с помощью create_engine(), соедините его с сессией, используя configure():
Такой класс Session будет создавать Session-объекты, которые привязаны к нашей базе.
Другие транзакционные параметры тоже можно определить вызовом sessionmaker()’а, но они будут описаны в следующей главе. Так, когда вам необходимо общение с базой, вы создаете объект класса Session:
Сессия здесь ассоциирована с SQLite, но у нее еще нет открытых соединений с этой базой. При первом использовании она получает соединение из набора соединений, который поддерживается engine и удерживает его до тех пор, пока мы не применим все изменения и/или не закроем объект сессии.
Добавление новых объектов [ править ]
Чтобы сохранить наш User-объект, нужно добавить его к нашей сессии, вызвав add():
Этот объект будет находиться в ожидании сохранения, никакого SQL-запроса пока послано не будет. Сессия пошлет SQL-запрос, чтобы сохранить Васю, как только это понадобится, используя процесс сброса на диск(flush). Если мы запросим Васю из базы, то сначала вся ожидающая информация будет сброшена в базу, а запрос последует потом.
Для примера, ниже мы создадим новый объект запроса (Query), который загружает User-объекты. Мы «отфильтровываем» по атрибуту «имя=Вася» и говорим, что нам нужен только первый результат из всего списка строк. Возвращается тот User, который равен добавленному:
На самом деле сессия определила, что та запись из таблицы, что она вернула, та же самая, что и запись, что она уже представляла в своей внутренней хеш-таблице объектов. Так что мы просто получили точно тот же самый объект, который только что добавили.
Та концепция ORM, что работает здесь, известная как карта идентичности, обеспечивает, что все операции над конкретной записью внутри сессии оперируют одним и тем же набором данных. Как только объект с неким первичным ключом появится в сессии, все SQL-запросы на этой сессии вернут те же самые объекты для этого самого первичного ключа. Будет выдана ошибка в случае попытки поместить в эту сессию другой, уже сохраненный объект с тем же первичным ключом.
Мы можем добавить больше User-объектов, использовав add_all()
А вот тут Вася решил, что его старый пароль слишком простой, так что давайте его сменим:
Сессия внимательно следит за нами. Она, для примера, знает, что Вася был модифицирован:
И что еще пара User’ов ожидают сброса в базу:
А теперь мы скажем нашей сессии, что мы хотим отправить все оставшиеся изменения в базу и применить все изменения, зафиксировав транзакцию, которая до того была в процессе. Это делается с помощью commit():
commit() сбрасывает все оставшиеся изменения в базу и фиксирует транзакции. Ресурсы подключений, что использовались в сессии, снова освобождаются и возвращаются в набор. Последовательные операции с сессией произойдут в новой транзакции, которая снова запросит себе ресурсов по первому требованию. Если посмотреть Васин атрибут id, что раньше был None, то мы увидим, что ему присвоено значение:
После того, как сессия вставит новые записи в базу, все только что созданные идентификаторы … будут доступны в объекте, немедленно или по первому требованию. В нашем случае, целая запись была перезагружена при доступе, так как после вызова commit() началась новая транзакция. SQLAlchemy стандартно обновляет данные от предыдущей транзакции при первом обращении с новой транзакцией, так что нам доступно самое последнее ее состояние. Уровень подгрузки настраивается, как описано в главе «Сессии».
Откат изменений [ править ]
Учитывая то, что сессия работает с транзакциями, мы можем откатить сделанные изменения. Давайте внесем два изменения, которые затем мы откатим; поменяем имя пользователя vasiaUser на Vaska:
и добавим ошибочного пользователя, fake_user:
Посылая запросы в сессию, мы можем увидеть, что они записаны в текущую транзакцию:
Откатывая, мы видим, что имя vasiaUser опять стало vasia, и fake_user был удален из транзакции:
посылая запрос SELECT, видно какие изменения произошли в базе данных:
Запросы [ править ]
Запрос создается посредством использования функции query() для сессии. Эта функция берет переменное число аргументов, которыми может быть любая комбинация классов и дескрипторов, созданных с помощью классов. Ниже, мы демонстрируем запрос, который загружает экземпляры User. В итеративном цикле возвращается список объектов User:
Запрос также поддерживает в качестве аргументов дескрипторы, созданные с помощью ORM. Каждый раз, когда запрашиваются разнообразные объекты классов или многоколоночные объекты в качестве аргументов функции query(), результаты возвращаются в виде кортежей:
Кортежи, которые возвращаются в запросе, являются именованными, и могут обрабатываться, как обычные объекты Python’а. Имена такие же, как и имена атрибутов для атрибутов, и имена классов для классов:
Вы можете определять свои имена, используя конструкцию label() для скалярных атрибутов и aliased() для классов:
Базовые операции с запросами включают в себя LIMIT и OFFSET, которые удобно использовать со срезами массивов из Python, и обычно в сочетании с ORDER BY:
и фильтруя результаты, которые выполнены либо с помощью filter_by(), которая использует ключевые аргументы:
…либо filter(), которая использует более подходящие для SQL конструкции языка. Это позволяет использовать более привычные операторы Python’а с атрибутами класса вашего отображения класса:
Объект запроса является полностью генеративным(порождающим), а это означает, что каждый вызов метода возвращает объект запроса, для которого можно добавить дополнительные ограничения. Например, чтобы получить пользователей с именем \»vasia\» и полным именем \»Vasiliy Pupkin\», вы можете повторно использовать функцию filter(), которая объединит критерии отбора, используя AND



