Тонкости Javascript/Node.js. Увеличиваем производительность в десятки раз
Вступление
Появилась необходимость обмениваться сообщениями между сервером и клиентом в бинарном виде, но в формате JSON в конечном итоге. Начал я гуглить, какие существуют библиотеки упаковки в бинарный вид. Пересмотрел немало: MesssagePack, Bson, protobuf, capnproto.org и другие. Но эти все библиотеки позволяют паковать и распаковывать готовые бинарные пакеты. Не очень копался, возможно ли делать парсер входящего трафика по кускам. Но суть не в этом. С такой задачей никогда не сталкивался и решил поиграться с нодой и сделать свой. Куда же без костылей и велосипедов? И вот с какими особенностями Node.js я столкнулся…
Написал я пакер и запустил…
4300. Удивился… Почему так долго? В то время, как код:
350. Не понял. Начал копать свой код и искать, где же много ресурсов используется. И нашел.
Выдает 1908. Вы скажете: да это не много на 1000000 повторений. А если я скажу, что много? Выполним такой код:
Выдает 16. Мои коллеги тоже возмутились, но и заметили, что функция же создается динамически и сразу уничтожается, ты ее вынес и нет такой нагрузки. Из эксперимента вывод: динамические фунции не кешируюся в бинарном виде. Я согласился и возразил: да, но нет ни переменных в SCOPE ничего используемого внутри нее. Похоже, движок гугла всегда копирует SCOPE.
Ок. Провел оптимизацию этой фунциональности и запустил… и все равно. Выдал
3000. Опять удивился. И снова полез копать… и обнаружил уже другой прикол.
Выдал 34. Теперь, допустим, нам надо внутри abc создать Array:
Выдал 1826. Смеркалось… А если нам надо 3 массива?
Выдал 5302! Вот это приколы. Казалось, SCOPE мы не используем, а создание пустого массива должно занимать вообще копейки. Не тут то было.
Думаю… А заменю-ка я на объекты. Результат получше, но не намного. Выдал 1071.
А теперь фокус. Многие скажут: ты же опять выносишь функцию. Да. Но фокус в другом.
Многие заметят и скажут: будет такое же время. А не тут то было. Выдал 25. Хотя массивы создавались столько же раз. Делаем вывод: создание массивов в динамической функции тратит много ресурсов. Вопрос: почему?
Теперь вернемся к первой проблеме. Но с другой стороны. Вынесем Array:
И я был прав. Выдал 58. С выносом всей фунции выдавал 16. Т.е. создание функции не особо ресурсоемкий процесс. Также опровергаем прошлый вывод:
бинарный код функций все же кешируется в памяти. А создание объектов в динамической функции занимает много времени.
движок гугла при каждом запуске создает новые объекты и заполняет необходимыми значениями, а потом уже вычисляет выражение, что не хорошо.
Оптимизация node.js приложения
Дано: старое http node.js приложение и возросшая нагрузка на него.
Стандартные решения проблемы: докинуть серверов, все переписать с 0, оптимизировать уже написанное.
Давайте попробуем пойти путем оптимизации и разобраться, как можно найти и улучшить слабые места приложения. А быть может ускориться не трогая ни строчки кода 🙂
Всех заинтересованных добро пожаловать под кат!
Для начала определимся с методикой тестирования производительности. Нас будет интересовать количество обслуженных запросов за 1 секунду: rps.
Запускать будем приложение в режиме 1 воркера (1 процесса), замеряя производительность старого кода и кода с оптимизациями — абсолютная производительность не важна, важна сравнительная производительность.
В типичном приложении с множествами разных роутов логично сначала найти самые загруженные запросы, на обработку которых тратится большая часть времени. Утилы вида request-log-analizer или множество подобных позволят извлечь эту информацию из логов.
С другой стороны, можно взять реальный список запросов и пулять их все (например с помощью yandex-tank-а) — получим достоверный профиль нагрузки.
Но делая множество итераций оптимизации кода, куда удобнее использовать более простой и быстрый инструмент и один конкретный тип запросов (а после оптимизации одного запроса изучать следующий, и т.д.). Мой выбор — wrk. Тем более что в моем случае количество роутов не велико — проверить все по одному не сложно.
Сразу надо оговорится, что в плане блокирующих запросов, ожидания БД и т.п. приложение уже оптимизировано, все упирается в cpu: при тестах воркер потребляет 100% cpu.
На продашен серверах используется node.js версии 6 — с неё и начнем:
Пробуем на 8й ноде:
Requests/sec: 2308
10я нода:
Requests/sec: 2590
Разница очевидна. Ключевую роль тут играет обновление версии v8 — множество плохо оптимизирующегося v8 кода осталось в прошлом. И чтобы не бороться с ветряными мельницами исчезнувшими в node.js v8 — лучше сразу обновиться, а потом уже заниматься оптимизацией кода.
Примерно так выглядит flamegraph тестируемого кода до оптимизаций:

Внизу фильтры, оставляем app, deps — только код приложения и сторонних модулей.
Чем шире полоска — тем больше времени потрачено на выполнения этой функции (включая вложенные вызовы).
Разбираться будем с центральной, самой большой частью.
В первую очередь подсвечиваем неоптимизированные функции. У меня в приложении таких нашлось немного.
Далее, верхние функции — типичные кандидаты на оптимизацию. Остальные же функции выстроились горкой с относительно равномерными ступеньками — каждая функция вкладывает небольшую долю задержек, явного лидера нет.
Дальше возможен простой алгогритм действий: оптимизировать самые широкие функции, переходя от одной к другой. Но я выбрал другой подход: оптимизировать начиная от точки входа в приложения (обработчик запроса в http.createServer). В конце исследуемой функции вместо вызова следующих функций я завершаю обработку запроса, отвечая ответом-пустышкой, и изучаю производительность именно этой функции. После её оптимизации ответ-пустышка перемещается дальше по стеку вызовов к следующей функции и т.д.
Удобное следствие такого подхода: можно видеть rps в идеальных условиях (при работающей только одной стартовой функцией rps близок к максимальному rps-у hellow world node.js приложения), и при дальнейшем перемещении заглушки-ответа вглубь приложения наблюдать вклад исследуемой функции в падение производительности в rps-ах.
Итак, оставляем только стартовую функцию, получаем:

Подключая фильтры core, v8 можно увидеть, что практически вся исследуемая функция состоит из отправки ответа, логгирования и других слабо оптимизируемых вещей — едем дальше.
Переходим к следующей функции:
Requests/sec: 16111
Ничего не изменилось — погружаемся дальше:
Requests/sec: 13330 
Наш клиент! Видно что задействованная функция getByUrl занимает значимую часть стартовой функции — что хорошо коррелирует с проседанием rps.
Смотрим внимательно что в ней происходит (включаем core, v8):
Много чего происходит… курим код, оптимизируем:
В данном случае простой for значительно быстрее for..in
Получаем Requests/sec: 16015

Визуально функция «сдулась» и занимает значительно меньшую долю от стартовой функции.
В детальной информации по функции так же все значительно упростилось:
Идем дальше, к следующей функции
В этой функции много array функций и, несмотря на существенное ускорение в последних версиях node.js, они все еще медленней простых циклов: меняем [].map и filter. на обычный for и получаем

И так раз за разом, для каждой следующей функции.
Еще несколько пригодившихся оптимизаций: для хешей с динамически изменяемым набором ключей new Map() может быть на 40% быстрее обычного <>;
Math.round(el*100)/100 в 2 раза быстрее чем toFixed(2).
В flamegraph-е для core и v8 функций можно увидеть как и малопонятные записи, так и вполне говорящие StringPrototypeSplit или v8::internal::Runtime_StringToNumber, и, если это значимая часть выполнения кода, попытаться оптимизировать, например просто переписать код, не выполняющий эти операции.
Например, замена split на несколько вызовов indexOf и substring может давать двойной выигрыш в производительности.
Отдельная большая и сложная тема — jit оптимизация, а вернее деоптимизированные функции.
При наличии большой доли таких функций надо будет разбираться и с ними.
Например, строчки вида
deoptimizing (DEOPT soft): begin 0x2bcf38b2d079 = 10? val: ‘0’+val;
return (val >= 10? »: ‘0’)+val;
Для старого v8 движка есть достаточно много информации по причинам и способах борьбы с деоптимизацией функций:
Но многие из проблем уже не актуальны для нового v8.
Так или иначе, после всех оптимизаций удалось получить Requests/sec: 9971, т.е. ускорится примерно в 2 раза за счет перехода на свежую версию node.js, и еще в 4 раза за счет оптимизации кода.
Надеюсь, этот опыт будет полезен кому-нибудь еще.
Делаем Node.js быстрым: инструменты, техники и советы для создания эффективных серверов на Node.js Часть первая
Node очень универсальная платформа, однако именно создание сетевых процессов одно из основных её применений. В этой статье мы сосредоточимся на профилировании наиболее распространённого из них: веб-сервера HTTP.
Если вы достаточно долго работали с Node.js, тогда вы наверняка сталкивались с неожиданными проблемами быстродействия. JavaScript событийный, асинхронный язык. Это затрудняет рассуждения о производительности, позже мы в этом убедимся. Растущая популярность Node.js выявила необходимость в инструментах, методах и мышлении, подходящих для ограничений серверного JavaScript.
Если говорить о производительности, то, что работает в браузере, не всегда подходит для Node.js. Так, как же нам убедиться, что реализация Node.js быстра и соответствует задаче? Давайте рассмотрим практический пример.
Нам понадобится инструмент, который сможет нагрузить сервер большим количеством запросов для измерения производительности. Например, мы можем использовать AutoCannon:

Apache Bench (ab) и wrk2 также хорошие инструменты для подобных целей, но AutoCannon написан на Node. Он обеспечивает аналогичную (или иногда большую) нагрузку и очень прост в установке на Windows, Linux и Mac OS X.
После того, как мы измерили базовую производительность, и решили, что процесс можно ускорить, нам понадобится какой-то способ диагностики проблем с процессом. Отличным инструментом для диагностики различных проблем производительности является Node Clinic, который также может быть установлен с помощью npm:

Эта команда установит пакет инструментов. А мы в примере будем использовать Clinic Doctor и Clinic Flame (wrapper 0x).
Примечание: для этого практического примера нам понадобится Node 8.11.2 или выше.
index.js файл для нашего сервера выглядит так:

Этот типичный сервер для обслуживания динамического контента, который кэшируется на стороне клиента. Это достигается с помощью etagger middleware, который вычисляет ETag загаловок для последнего состояния содержимого.
Файл util.js предоставляет исполняющие части, которые обычно используются в подобных сценариях, функцию для извлечения релевантного контента из бэкенда, etag middleware и функцию timestamp, которая выдаёт тайм метки поминутно:

Однако этот код не лучший вариант для практики! В этом коде есть несколько проблем, мы найдем их по ходу измерений и профилирования приложения.
Профилирование
Чтобы начать профилировать, нам нужны 2 терминала, один для запуска приложения, а другой для тестирования нагрузкой.
На одном терминале, из папки app мы можем запустить:

На другом терминале профилировать его так:

Это откроет 100 одновременных соединений и бомбардирует сервер запросами в течение десяти секунд.
Результаты должны быть примерно такими (запуск теста 10сек @ http://localhost:3000/seed/v1 –100 соединений):
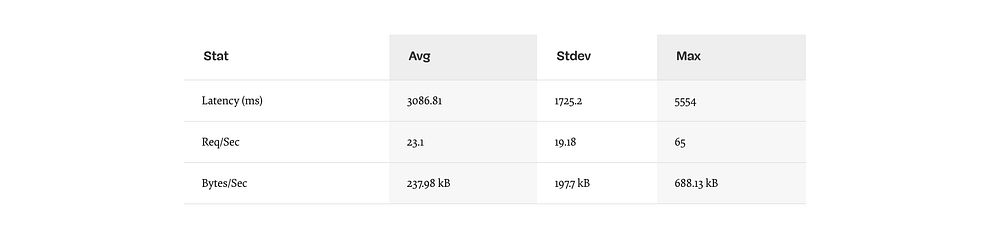
231 запрос за 10 секунд, 2,4 МБ чтения
Результаты будут отличаться в зависимости от машины. Однако, учитывая, что “Hello World” Node.js сервер легко обработает и тридцать тысяч запросов в секунду на этой машине, 23 запроса в секунду со средней задержкой, превышающей 3 секунды — это печально.
Диагностируем
Обнаруживаем проблемные места

Это создаст HTML-файл, который автоматически откроется в нашем браузере после завершения профилирования.
Результаты должны выглядеть примерно так:
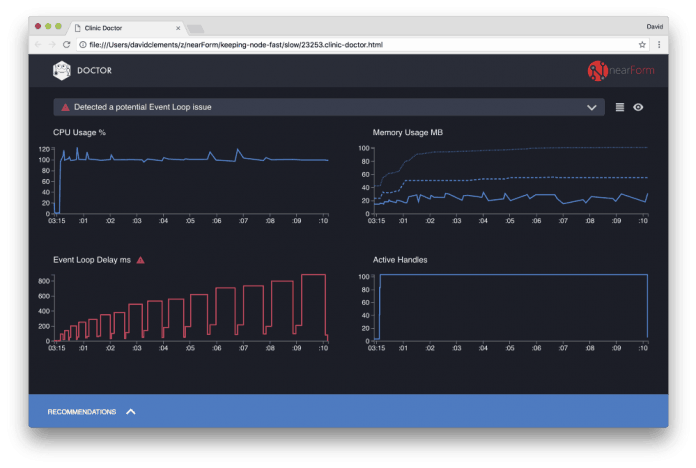
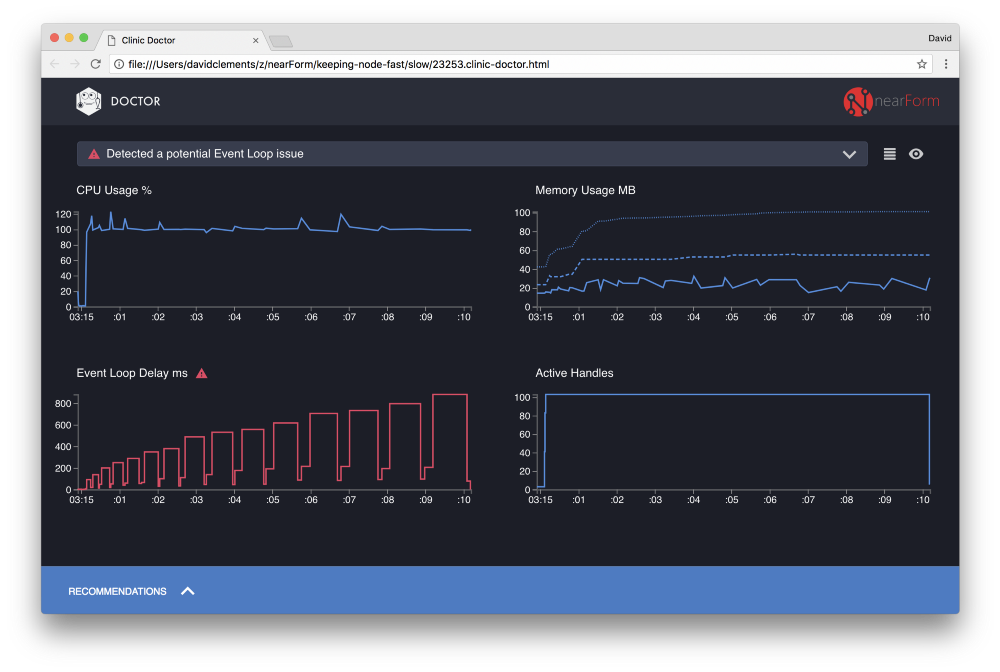 Результаты Clinic Doctor
Результаты Clinic Doctor
«Доктор» говорит нам, что у нас, вероятно, была проблема с циклом событий (Event Loop).
Вместе с сообщением в верхней части UI, мы также можем видеть, что диаграмма Event Loop красного цвета, и показывает постоянно увеличивающуюся задержку. Прежде чем мы углубимся в значение этого показателя, давайте сначала разберемся какой эффект оказывает эта проблем на остальные метрики.
Мы видим, что процессор стабильно находится на уровне или выше 100%, пока процесс упорно обрабатывает запросы из очереди. JavaScript движок Node.js (V8) в этом случае фактически использует два ядра процессора, потому что машина многоядерная и V8 использует два потока. Один для цикла обработки событий, а другой для «сбора мусора». Там, где мы видим пики нагрузки вплоть до 120% — это процесс собирает объекты, связанные с обработанными запросами.
Мы видим эту корреляцию на графике Memory. Сплошная линия на диаграмме Memory — это метрика Heap Used. Каждый раз, когда есть всплеск ЦП, мы видим проседание Heap Used, это показывает, что память освобождается.
Если щелкнуть панель Recommendations в нижней части экрана, мы увидим примерно следующее:
Временный меры
Анализ основных причин, серьезных проблем с производительностью, может занять некоторое время. В случае уже развернутого проекта стоит добавить защиту от перегрузки на серверы или службы. Идея защиты от перегрузки состоит в том, чтобы контролировать задержку Event Loop (помимо прочего) и отвечать ошибкой “503 Service Unavailable”, если порог пройден. Это позволяет балансировщику нагрузки переключаться на другие инстансы или в худшем случае пользователям придется обновлять страницу. Модуль защиты от перегрузки может обеспечить это с минимальным оверхедом для Express, Koa, и Restify. Фреймфорк Hapi может обеспечить такую же защиту с помощью настройки конфигурации.
В продолжении статьи, после диагностики производительности с помощью Clinic Doctor, мы приступим к анализу метрик используя flame graph. Найдём проблемные места в нашем коде и начнём его исправлять.
Ускоряем node.js: нативные модули и CUDA
Иногда разработчики различных веб-проектов сталкиваются с необходимостью обработки больших объемов данных или использованием ресурсозатратного алгоритма. Старые инструменты уже не дают необходимой производительности, приходится арендовать/покупать дополнительные вычислительные мощности, что подталкивает к мысли переписать медленные участки кода на C++ или других быстрых языках.
В этой статье я расскажу о том, как можно попробовать ускорить работу Node.JS (который сам по себе считается довольно быстрым). Речь пойдет о нативных расширениях, написанных с помощью C++.
Коротко о расширениях
Итак, у вас имеется веб-сервер на Node.JS и вам поступила некая задача с ресурсозатратным алгоритмом. Для выполнения задачи было принято решение написать модуль на C++. Теперь нам надо разобраться с тем, что же это такое — нативное расширение.
Архитектура Node.JS позволяет подключать модули, упакованные в библиотеки. Для этих библиотек создаются js-обертки, с помощью которых вы можете вызывать функции этих модулей прямо из js-кода вашего сервера. Многие стандартные модули Node.JS написаны на C++, однако это не мешает пользоваться ими с таким удобством, как будто они были бы написаны на самом javascript’e. Вы можете передавать в свое расширение любые параметры, отлавливать исключения, выполнять любой код и возвращать обработанные данные обратно.
По ходу статьи мы разберемся в том, как создавать нативные расширения и проведем несколько тестов производительности. Для тестов возьмем не сложный, но ресурсозатратный алгоритм, который выполним на js и на C++. Например — вычислим двойной интеграл.
Что считать?
Возьмем функцию: 
Эта функция задает следующую поверхность:
Для нахождения двойного интеграла нам необходимо найти объем фигуры, ограниченной данной поверхностью. Для этого разобьем фигуру на множество параллелепипедов, с высотой, равной значению функции. Сумма их объемов даст нам объем всей фигуры и численное значение самого интеграла. Для нахождения объема каждого параллелепипеда разобьем площадь под фигурой на множество маленьких прямоугольников, затем перемножим их площади на значение нашей функции в точках на краях этих прямоугольников. Чем больше параллелепипедов, тем выше точность.
Код на js, который выполняет это интегрирование и показывает нам время выполнения:
Подготовка к написанию расширения
Нативное расширение
Все настроено, приступаем к написанию кода.
Добавляем этот код к уже готовому проекту на Node.JS, вызываем функции, сравниваем:
Получаем результат:
JS result = 127.99999736028109
JS time = 127
Native result = 127.999997
Native time = 103
Разница минимальна. Увеличим количество итераций по осям в 8 раз. Получим следующие результаты:
JS result = 127.99999995875444
JS time = 6952
Native result = 128.000000
Native time = 6658
Выводы
Результат удивляет. Мы не получили практически никакого выигрыша. Результат на Node.JS получается почти точно таким же, какой получается на чистом С++. Мы догадывались что V8 быстрый движок, но чтоб настолько… Да, даже чисто математические операции можно писать на чистом js. Потеряем мы от этого немного, если вообще что-то потеряем. Чтобы получить выигрыш от нативного расширения мы должны использовать низкоуровневую оптимизацию. Но это будет уже слишком. Выигрыш в производительности от нативного модуля далеко не всегда окупит затраты на написание сишного или даже ассемблерного кода. Что же делать? Первое что приходит на ум — использование openmp или нативных потоков, для параллельного решения задачи. Это ускорит решение каждой отдельно взятой задачи, но не увеличит количество решаемых задач в единицу времени. Так что такое решение подойдет не каждому. Нагрузка на сервер не снизится. Возможно мы так же получим выигрыш при работе с большим объемом памяти — у Node.JS все таки будут дополнительные накладные расходы и общий занимаемый объем памяти будет больше. Но память сейчас далеко не так критична, как процессорное время. Какие выводы мы можем сделать из данного исследования?
We need to go deeper
А давайте-ка все таки попробуем ускорить работу нашего кода? Раз у нас есть доступ из нативного расширения к чему угодно, то есть доступ и к видеокарте. Используем CUDA!
Напишем обработчик на js:
Запустим тестирование на следующих данных:
JS result = 127.99999736028109
JS time = 119
Native result = 127.999997
Native time = 122
CUDA result = 127.999997
CUDA time = 17
Как мы видим, обработчик на видеокарте уже показывает сильный отрыв. И это при том, что результаты работы каждого потока видеокарты я суммировал на CPU. Если написать алгоритм, полностью работающий на GPU, без использования центрального процессора, то выигрыш в производительности будет еще ощутимее.
Протестируем на следующих данных:
Получим результат:
JS result = 127.99999998968899
JS time = 25401
Native result = 128.000000
Native time = 28405
CUDA result = 128.000000
CUDA time = 3568
Делаем Node.js быстрым: инструменты, техники и советы для создания эффективных серверов на Node.js Часть третья.

Aug 31, 2018 · 4 min read
Оптимизируем
Теперь, когда мы обнаружили проблемные области, давайте посмотрим, можем ли мы сделать сервер быстрее.
Лёгкий и быстрый способ
Давайте вернем код слушателя server.on (вместо пустой функции) и используем правильное имя для проверки условия. Наша функция etagger выглядит вот так:

Профилируем снова, чтобы проверить наши исправления. Запустите сервер на одном терминале:

Затем профилируем с AutoCannon:

Результат должен улучшится примерно в 200 раз. (запуск теста 10сек @ http://localhost:3000/seed/v1 — 100 подключений):
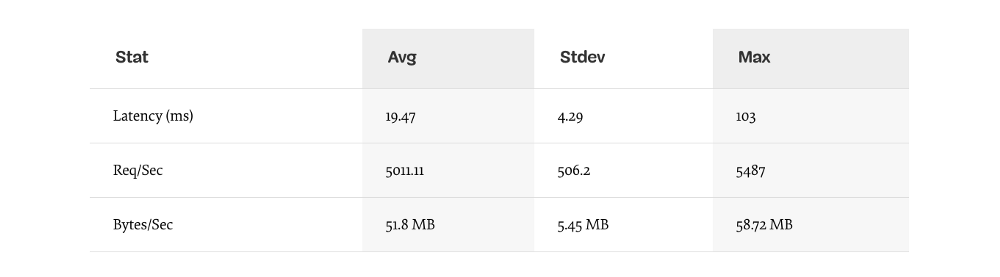
Важно сбалансироват ь потенциальное снижение стоимости сервера с затратами на разработку. Нам нужно определить, в контексте нашей ситуации, как далеко нам нужно зайти в оптимизации проекта. В противном случае, мы легко можем положить 80% усилий в 20% повышения скорости. Оправдывают ли это ограничения проекта?
В некоторых случаях было бы целесообразно достичь улучшения в 200 раз лёгким путём, потратив на это всего день. В других случаях мы, возможно, захотим сделать нашу реализацию настолько быстрой, насколько это возможно. Это действительно зависит от приоритетов проекта.
Один из способов контролировать расходы ресурсов — постановка цели. Например, улучшение в 10 раз или 4000 запросов в секунду. Имеет смысл исходить из потребностей бизнеса. Например, если затраты на сервер превышают бюджет на 100%, мы можем поставить цель улучшения в 2 раза.
Идём дальше
Если мы создадим новый flame graph нашего сервера, мы увидем что-то подобное:
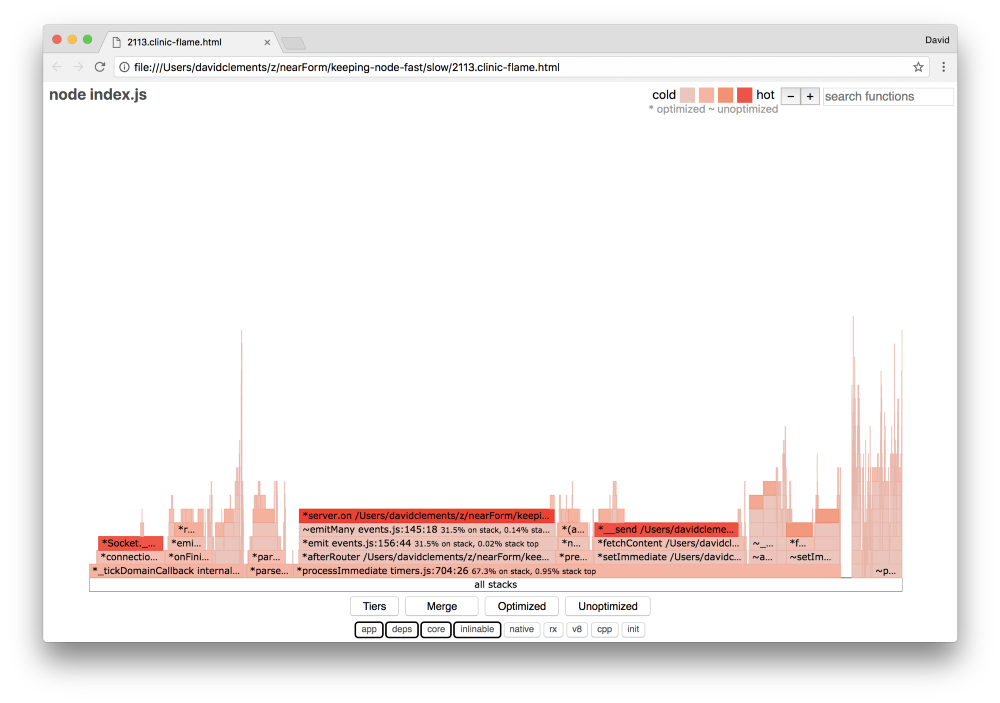
Слушатель событий по-прежнему bottleneck, он всё еще занимает одну треть процессорного времени во время профилирования (ширина составляет около трети всего графика).
Какие еще улучшения можно сделать, и стоит ли вносить изменения (учитывая связанные с ними последствия)?
В оптимизированной реализации, которая, тем не менее ограничена, могут быть достигнуты следующие характеристики (запуск теста 10сек @ http://localhost:3000/seed/v1 –10 подключений):
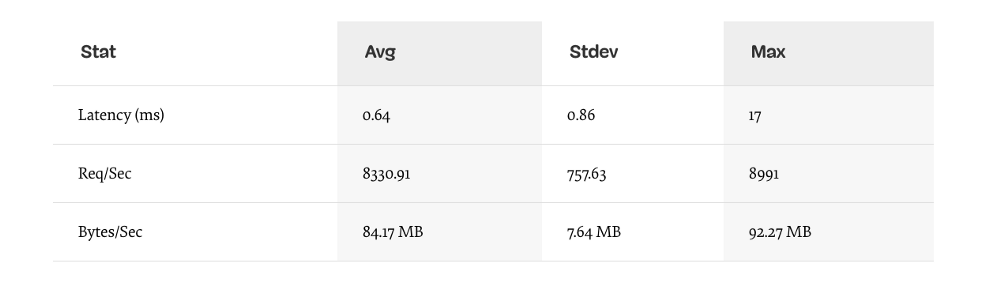
Улучшение в 1.6 раз это существенно, но оправданы ли усилия, изменения и нарушение кода, необходимые для достижения такого результата? Зависит от ситуации. Особенно по сравнению с 200-кратным улучшением оригинальной реализации после исправления одной ошибки.
Для достижения этого улучшения использовалась та же итеративная техника: профилирование, flame graph, анализ, debug, оптимизация. Код оптимизированного сервера можно найти здесь.
На последок, для достижения 8000 запросов/сек :
Давайте взглянем на flame graph после последних улучшений:
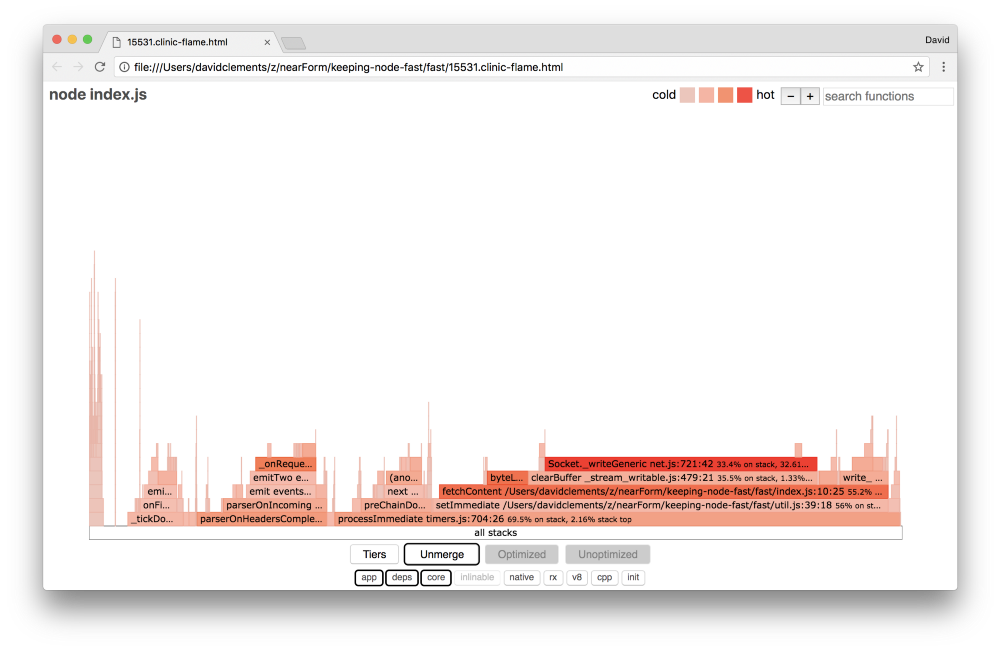
Предотвращение проблем с производительностью
В заключение приведу несколько рекомендаций по предотвращению проблем с производительностью перед развертыванием.
Используйте инструменты для отслеживания проблем с производительностью на этапе разработки. Они помогут отфильтровать баги, прежде чем они попадут в продакшн. Рекомендую использовать инструменты AutoCannon и Clinic (или их эквиваленты) в повседневной разработке.
Если покупаете фреймворк, разузнайте о его политике производительности. Если производительность не самая сильная сторона фреймворка, тогда важно проверить, соответствует ли он инфраструктурным практикам и бизнес-целям. Например, команда Restify явно (начиная с релиза седьмой версии) вложилась в повышение производительности библиотеки. Впрочем, если низкая стоимость и высокая скорость являются абсолютным приоритетом, рассмотрите Fastify. Его производительность на 17% выше, измерения проводил участник Restify.



