Математика для чайников. Матрицы и основные действия над ними

Определение матрицы
Матрица – это прямоугольная таблица элементов. Ну а если простым языком – таблица чисел.
Обычно матрицы обозначаются прописными латинскими буквами. Например, матрица A, матрица B и так далее. Матрицы могут быть разного размера: прямоугольные, квадратные, также есть матрицы-строки и матрицы-столбцы, называемые векторами. Размер матрицы определяется количеством строк и столбцов. Например, запишем прямоугольную матрицу размера m на n, где m – количество строк, а n – количество столбцов.
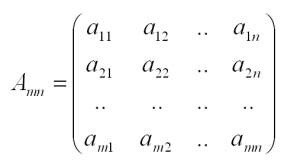
Что можно делать с матрицами? Складывать/вычитать, умножать на число, умножать между собой, транспонировать. Теперь обо всех этих основных операциях над матрицами по порядку.
Операции сложения и вычитания матриц
Сразу предупредим, что можно складывать только матрицы одинакового размера. В результате получится матрица того же размера. Складывать (или вычитать) матрицы просто – достаточно только сложить их соответствующие элементы. Приведем пример. Выполним сложение двух матриц A и В размером два на два.
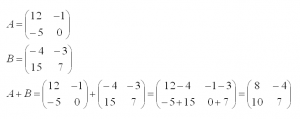
Вычитание выполняется по аналогии, только с противоположным знаком.
Умножение матрицы на число
На произвольное число можно умножить любую матрицу. Чтобы сделать это, нужно умножить на это число каждый ее элемент. Например, умножим матрицу A из первого примера на число 5:
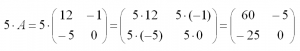
Операция умножения матриц
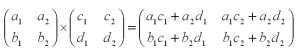
И пример с реальными числами. Умножим матрицы:
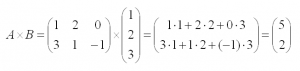
Операция транспонирования матрицы
Транспонирование матрицы – это операция, когда соответствующие строки и столбцы меняются местами. Например, транспонируем матрицу A из первого примера:
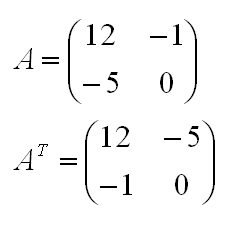
Определитель матрицы
Определитель, о же детерминант – одно из основных понятий линейной алгебры. Когда-то люди придумали линейные уравнения, а за ними пришлось выдумать и определитель. В итоге, разбираться со всем этим предстоит вам, так что, последний рывок!
Определитель – это численная характеристика квадратной матрицы, которая нужна для решения многих задач.
Чтобы посчитать определитель самой простой квадратной матрицы, нужно вычислить разность произведений элементов главной и побочной диагоналей.
Определитель матрицы первого порядка, то есть состоящей из одного элемента, равен этому элементу.
А если матрица три на три? Тут уже посложнее, но справиться можно.
Для такой матрицы значение определителя равно сумме произведений элементов главной диагонали и произведений элементов лежащих на треугольниках с гранью параллельной главной диагонали, от которой вычитается произведение элементов побочной диагонали и произведение элементов лежащих на треугольниках с гранью параллельной побочной диагонали.
К счастью, вычислять определители матриц больших размеров на практике приходится редко.
Правило умножения матриц: примеры с решением

Обновлено: 14 Июля 2021
Мы помним, что матрицы – это таблицы взаимосвязанных элементов, которые позволяют упростить математические вычисления и систематизировать определённую информацию. Их можно складывать, вычитать, умножать между собой. В этой статье подробнее остановимся на последнем алгоритме – матричном произведении.
Умножение матриц — определение
Матричное умножение – это одна из основных операций, которая проводится исключительно с согласованными матрицами.
При произведении матриц A и B получается новая матрица C. В математическом виде формула будет выглядеть так:
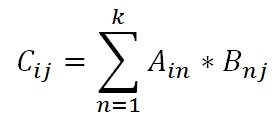
Но для начала разберёмся, что такое согласованные матрицы.
Согласованные матрицы
Согласованными матрицами называют матрицы вида A = [m ☓ n] и B = [n ☓ k], где количество столбцов А равно количеству строк В.
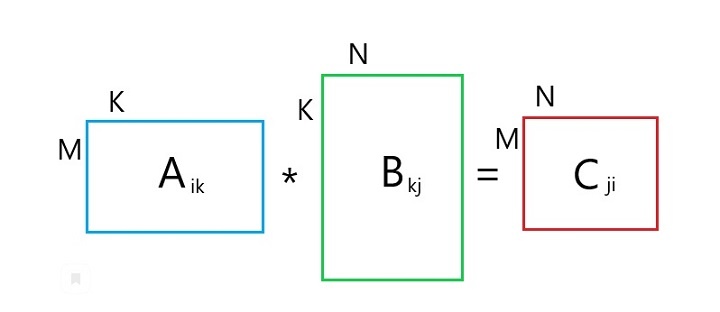
Индексы показывают координаты равных элементов.
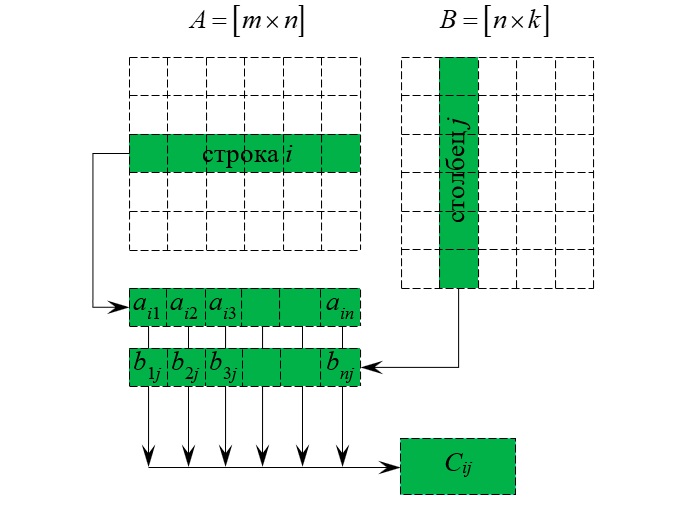
Для того, чтобы умножить А и В, нужно взять строку в первой матрице и столбец во второй, перемножить одинаковые элементы и сложить полученные произведения.
Основные свойства матричного произведения
Размеры, то есть количество строк (m) и столбцов (n), влияют на особенности матричного произведения. Следовательно, для двух главных видов – квадратных и прямоугольных – действуют разные свойства произведения. Однако умножение любого вида всегда некоммуникативное. Это означает, что матрицы нельзя менять местами (АВ ≠ ВА).
Умножение квадратных матриц
Для квадратных матриц существует единичная матрица Е. В ней элементы по главной диагонали равны единице, а оставшиеся – нулю. Произведение любой квадратной матрицы на неё не влияет на результат.
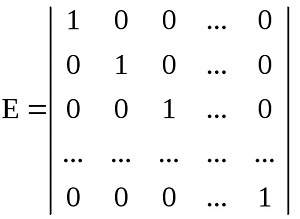
В математическом виде это выглядит так: ЕА = АЕ = А
Также существует обратная матрица А (-1), при умножении на которую исходная A = [m ☓ n] даёт в результате единичную матрицу E.
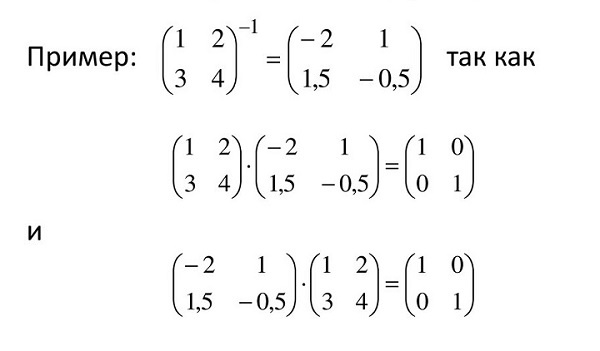
Следовательно, формула такова: АА(-1) = Е
Умножение прямоугольных матриц
Существуют четыре основных свойства умножения:
Напомним, что у нулевой матрицы все элементы равны нулю.
Произведение трех матриц
Произведение АВС можно получить двумя альтернативными способами:
Данное свойство называется ассоциативностью матричного умножения и действует на все виды согласованных матриц. Сами они не переставляются, меняется только порядок их умножения.
Умножение матрицы на число
Для умножения на число необходимо умножить каждый матричный элемент на это число:

Дроби вносить не нужно, поскольку они могут затруднить дальнейшие операции.
Умножение матрицы на вектор
Здесь работает правило «строка на столбец».
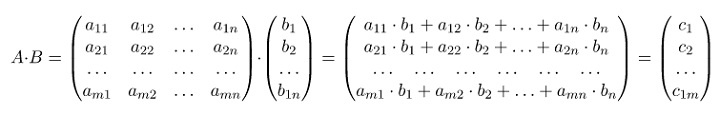
При умножении на вектор-столбец важно, чтобы количество столбцов в матрице совпадало с количеством строк в векторе-столбце. Результатом произведения будет вектор-столбец.
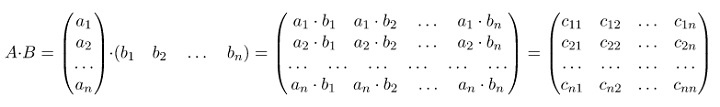
При умножении на вектор-строку матрица должна быть только вектором-столбцом. Важно, чтобы количество строк в векторе-столбце совпадало с количеством столбцов в векторе-строке. Результатом произведения будет квадратная матрица.
Примеры задач на умножение матриц
Задача №1: выполнить умножение и найти С, если A = [m ☓ n] и B = [n ☓ k] равны.
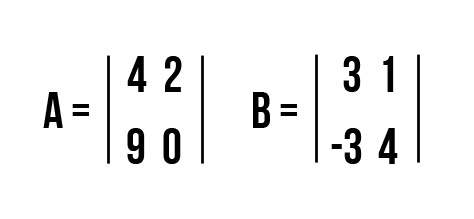
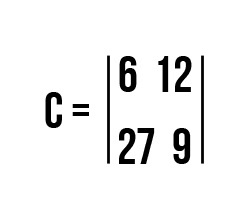
Задача №2: вычислить С, если А = [m ☓ n] и вектор-столбец В равны.
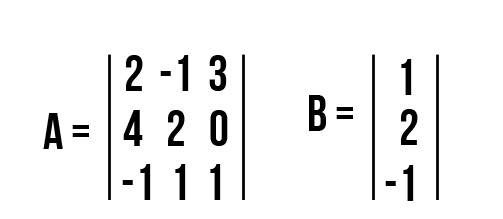
c21 = a11·b12 + a12·b22 = 4⋅1 + 2⋅2 + 0⋅2 = 8
c31 = a21·b11 + a22·b21 = −1⋅1 + 1⋅2 + 1⋅(−1) = 0
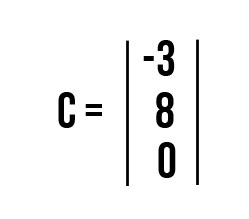
Изучение матричных операций очень увлекательное, но сложное занятие. Если у вас нет времени на учёбу, ФениксХэлп может помочь в решении контрольных и самостоятельных работ, написании статей и диссертаций.
Умножение матриц: эффективная реализация шаг за шагом

Введение
Умножение матриц — это один из базовых алгоритмов, который широко применяется в различных численных методах, и в частности в алгоритмах машинного обучения. Многие реализации прямого и обратного распространения сигнала в сверточных слоях неронной сети базируются на этой операции. Так порой до 90-95% всего времени, затрачиваемого на машинное обучение, приходится именно на эту операцию. Почему так происходит? Ответ кроется в очень эффективной реализации этого алгоритма для процессоров, графических ускорителей (а в последнее время и специальных ускорителей матричного умножения). Матричное умножение — один из немногих алгоритмов, которые позволяет эффективно задействовать все вычислительные ресурсы современных процессоров и графических ускорителей. Поэтому не удивительно, что многие алгоритмы стараются свести к матричному умножению — дополнительная расходы, связанные с подготовкой данных, как правило с лихвой окупаются общим ускорением алгоритмов.
Так как реализован алгоритм матричного умножения? Хотя сейчас существуют множество реализаций данного алгоритма, в том числе и в открытых исходных кодах. Но к сожалению, код данных реализаций (большей частью на ассемблере) весьма сложен. Существует хорошая англоязычная статья, подробно описывающая эти алгоритмы. К моему удивлению, я не обнаружил аналогов на Хабре. Как по мне, этого повода вполне достаточно, чтобы написать собственную статью. С целью ограничить объем изложения, я ограничился описанием однопоточного алгоритма для обычных процессоров. Тема многопоточности и алгоритмов для графических ускорителей явно заслуживает отдельной статьи.
Процесс изложения будет вестись ввиде шагов с примерами по последовательному ускорению алгоритма. Я старался писать максимально упрощая задачу, но не более того. Надеюсь у меня получилось…
Постановка задачи (0-й шаг)
В общем случае функция матричного умножения описывается как:
Где матрица A имеет размер M х K, матрица B — K х N, и матрица C — M х N.

Мы без ущерба для изложения, можем считать, что a = 0 и b = 1:
Ее реализация на С++ «в лоб» по формуле будет выглядеть следующим образом:
120 GFLOPS (float-32) если ограничится использованием AVX2/FMA и
200 GFLOPS при использовании AVX-512). Так, что нужно предпринять, чтобы приблизится к теоретическому пределу? Далее мы в ходе ряда последовательных оптимизаций придем к решению, которое во многом воспроизводит то, что используется во многих стандартных библиотеках. В процессе оптимизации, я буду задействовать только AVX2/FMA, AVX-512 я касаться не буду, так как их распостраненность пока невелика.
Устраняем очевидные недостатки (1-й шаг)
Сначала устраним самые очевидные недостатки алгоритма:
Результат тестовых замеров показывает время выполнения в 250 мс, или 11.4 GFLOPS. Т.е. такими небольшими правками мы получили ускорение в 8 раз!
Векторизуем внутренний цикл (2-й шаг)
Запускаем тесты, получаем время 217 мс или 13.1 GFLOPS. Упс! Ускорение всего на 15%. Какже так? Тут нужно учитывать, два фактора:
Дальнейшие наши шаги по оптимизации алгоритма будут направлены на минимизацию доступа в память.
Пишем микроядро (3-й шаг)
В предыдущей версии на 1 FMA операцию приходится 2 загрузки и 1 выгрузка.
Больше всего загрузок и выгрузок происходит с результирующей матрицей С: данные из нее нужно загрузить, прибавить к ним произведение C[i][j] += A[i][k]*B[k][j], а потом сохранить. И так много раз. Наиболее быстрая память, с которой может работать процессор — это его собственные регистры. Если мы будем хранить результирующее значение матрицы С в регистре процессора, то в процессе расчета нужно будет подгружать только значение матриц A и B. Теперь у нас на 1 FMA операцию приходится только 2 загрузки.
Если мы будем хранить в регистрах значения двух соседних столбцов матрицы C[i][j] и C[i][j+1], то сможем повторно использовать загруженное значение матрицы A[i][k]. И на 1 FMA операцию потребуется только 1.5 загрузки. Кроме того, сохраняя результат в 2 независимых регистра, мы позволим процессору выполнять 2 FMA операции за такт. Аналогично можно хранить в регистрах значения двух соседних строк — тогда будет осуществляться экономия на загрузке значений матрицы B.
Всего настольные процессоры Интел начиная с 2-го поколения имеют 16 256-bit векторных регистров (справедливо для 64-bit режима процессора). 12 из них можно использовать для хранения кусочка результирующей матрицы С размером 6×16. В итоге мы сможем выполнить 12*8 = 96 FMA операций загрузив из памяти только 16 + 6 = 22 значений. И того нам удалось сократить доступ к памяти с 2.0 до 0.23 загрузки на 1 FMA операцию — почти в 10 раз!
Функция которая осуществляет вычисление такого маленького кусочка матрицы С, обычно называется микроядром, ниже приведен пример такой функции:
Введем небольшую вспомогательную функцию для инициализации начального значения матрицы С:
Здесь lda, ldb, ldc — длина строчки (Leading Dimension в общем случае) соответсвующей матрицы.
Тогда функция умножения примет следующий вид:
Запускаем ее и получаем время исполнения 78.5 мс или 36.2 GFLOPS. Т.е. использование микроядра позволило ускорить матричное умножение почти в 3 раза. Но полученное быстродействие все еще далеко от максимального. Где теперь узкое место?
Переупорядочиваем матрицу B (4-й шаг)
Микроядро за каждую итерацию загружает два 256-bit вектора из матрицы B.
Причем каждый раз из новой строчки. Это делает невозможным для процессора эффективное кеширование этих данных. Для исправления этой ситуации сделаем два изменения:
Здесь стоит отметить, что загрузка и выгрузка AVX векторов оптимально работает при выровненных данных, потому используются специальные функции для выделения памяти.
Функция переупорядочивания матрицы B:
Ну и собственно 4-я версия функции gemm:
Результаты тестирования (29.5 мс или 96.5 GFLOPS) показывают, что мы на правильном пути. Фактически достигнуто около 80% от теоретически возможного максимума.
Победа? К сожалению нет. Просто размер матриц, который мы использовали для тестирования (M=N=K=1152) оказался удобным для данной версии алгоритма. Если увеличить К в 100 раз (M=1152, N=1152, K=115200), то эффективность алгоритма упадет до 39.5 GFLOPS — почти в 2.5 раза.
Локализуем данные в кэше L1 (5-й шаг)
Так почему же с ростом параметра K, падает эффективность алгоритма? Ответ кроется в величине буфера, который мы использовали для хранения переупорядоченных значений B. При больших значениях K он просто не влазит в кэш процессора. Решением проблемы будет ограничение его величины до размера кэша данных L1. Для процессоров Интел размер кэша данных L1 составляет 32 kb. C ограничением размера буфера, микроядро будет пробегать не по всем значениям K, а только по диапазону, который влазит в L1 кэш. Результаты промежуточных расчетов матрицы С будут храниться в основной памяти.
Введем макроядро — вспомогательную функцию, которая производит расчеты над областью данных, которые влазят в кэш:
В главной функции у нас добавится цикл по K, в котором мы будем вызывать макроядро:
Результаты замеров показывают, что мы движемся в правильном направлении: для (M=1152, N=1152, K=115200) производительность алгоритма составила 78.1 GFLOPS. Это значительно лучше, чем в прошлой версии, но все еще хуже, чем для матрицы средних размеров.
Переупорядочиваем матрицу A и локализуем в кэше L2 (6-й шаг)
Ограничив размер K, который обрабатывается за один проход микроядра, мы сумели локализовать данные матрицы B в кэше L1. Данных, которые подгружаются из матрицы A почти в три раза меньше. Но давайте попробуем локализовать и их, заодно переупорядочив данные, чтобы они лежали последовательно. Напишем для этого специальную функцию:
Так как, данные матрицы A теперь идут последовательно, то параметр lda в макроядре нам больше не нужен. Также поменялись параметры вызова микроядра:
Размер буфера для переупорядоченной матрицы A ограничиваем размером L2 кэша процессора (он обычно составляет от 256 до 1024 kb для разных типов процессоров). В главной функции добавляется дополнительный цикл по переменной M:
Результаты тестовых замеров для (M=1152, N=1152, K=115200) — 88.9 GFLOPS — приблизились еще на один шаг к результату для матриц среднего размера.
Задействуем кэш L3 (7-й шаг)
В процессорах помимо кэша L1 и L2 еще часто бывает кэш L3 (обычно его размер составляет 1-2 MB на ядро). Попробуем задействовать и его, например, для хранения переупорядоченных значений матриц B, чтобы избежать лишних вызовов функции reorder_b_16. В функции макроядра появится дополнительные параметр reorderB, который будет сообщать о том, что данныe матрицы B уже упорядочены:
В основной функции добавится цикл по N:
Результаты замеров для (M=1152, N=1152, K=115200) дают результат в 97.3 GFLOPS. Т.е. мы даже немного превысили результат для матриц среднего размера. Фактически мы получили универсальный алгоритм (на самом деле нет, про ограничения в следующем разделе), который практически одинаково эффективно (порядка 80% от теоретически достижимого макимума) работает для любого размера матриц. На этом предлагаю остановиться и описать, что у нас в итоге получилось.
Общая схема алгоритма
На рисунке ниже приведена схема получившегося алгоритма:
Микро ядро
Макро ядро
Основная функция
Что осталось за кадром?
В процессе изложения основных принципов, которые используются в алгоритме матричного умножения, я сознательно упростил задачу, иначе она бы не влезла ни в одну статью. Ниже я опишу некоторые вопросы, которые неважны для понимания основной сути алгоритма, но очень важны для практической их реализации:
Заключение
Приведенный алгоритм матричного умножения позволяет эффективно задействовать ресурсы современных процессоров. Но он наглядно показывает, что максимальная утилизация ресурсов современных процессоров — это далеко нетривиальная задача. Подход с использованием микроядер и максимальной локализации данных в кэше процессора можно с успехом использовать и для других алгоритмов.
Код проекта с алгоритмами из статьи можно найти на Github.
Матричное умножение. Медленное достижение мифической цели
В недавней работе был установлен новый рекорд скорости по умножению двух матриц. Она также знаменует и конец эпохи для метода, который ученые применяли для исследований на протяжении десятилетий.

Математики стремятся к достижению мифической цели — второй степени (exponent two), то есть к умножению пары матриц n х n всего за n 2 шагов. Исследователи подбираются все ближе к своей цели, но получится ли у них когда-нибудь достичь ее?
Для специалистов в области Computer Science и математиков сама идея о «второй степени» связана с представлениями о совершенном мире.
«Трудно разграничить научное мышление и беспочвенные мечтания», — признается Крис Уманс из Калифорнийского технологического института. «Я хочу, чтобы степень была равна двум, потому что это красиво».
С точки зрения необходимого количества шагов «вторая степень» — это идеальная скорость выполнения одной из самых фундаментальных математических операций — матричного умножения. Если вторая степень достижима, то матричное умножение получится выполнять максимально быстро, насколько это физически возможно. Если это не так, то мы застряли в мире, который не соответствует нашим мечтам.
Матрицы представляют собой массивы чисел. Когда две матрицы согласованы (число столбцов в первом сомножителе равно числу строк во втором), их можно перемножить, чтобы получить третью. Например, если вы начнете с пары матриц 2 х 2, их произведение также будет матрицей 2 х 2, содержащей четыре элемента. В более общем смысле, произведение пары матриц размером n х n представляет собой другую матрицу размером n х n с n 2 элементами.
И хотя никто точно не знает, можно ли этого достичь, исследователи продолжают продвигаться в этом направлении.
Статья, опубликованная в октябре, подбирается к цели еще ближе и описывает самый быстрый на данный момент метод умножения двух матриц. Результат, который получили Джош Алман, докторант Гарвардского университета, и Вирджиния Василевска Уильямс из Массачусетского технологического института, уменьшает степень предыдущего лучшего показателя примерно на одну стотысячную. Это действительно большое достижение в данной области, добытое кропотливым трудом.
Чтобы получше разобраться в этом процессе и понять, как его можно усовершенствовать, давайте начнем с пары матриц 2 х 2, A и B. При вычислении каждого элемента их произведения вы используете соответствующую строку из A и соответствующий столбец из B. Чтобы получить верхний правый элемент, умножьте первое число в первой строке A на первое число во втором столбце B, затем умножьте второе число в первой строке A на второе число во втором столбце B и сложите эти два произведения.
Самуэль Веласко / Quanta Magazine
Эта операция известна как получение «скалярного произведения» строки со столбцом (иногда называется «внутренним произведением»). Чтобы вычислить другие элементы в произведении матриц, повторите процедуру с соответствующими строками и столбцами.
В целом, классический метод умножения матриц 2 х 2 состоит из восьми умножений и нескольких сложений. Как правило, этот способ умножения двух матриц размера n х n требует n 3 умножений.
С увеличением размера матриц количество умножений, необходимых для нахождения их произведения, растет намного быстрее, чем количество сложений. Чтобы найти произведение матриц 2 х 2 требуется всего восемь промежуточных умножений, а чтобы найти произведение матриц 4 х 4 их требуется уже 64. Однако количество сложений, необходимых для получения суммы этих матриц, не так значительно отличается. Обычно количество сложений равно количеству элементов в матрице, то есть четыре для матриц 2 х 2 и 16 для матриц 4 х 4. Эта разница между сложением и умножением позволяет понять, почему исследователи измеряют скорость умножения матриц исключительно с точки зрения количества требуемых умножений.
«Умножения — это наше всё, — утверждает Уманс, — Показатель степени в итоге полностью зависит только от количества умножений. Сложения в некотором смысле исчезают».
На протяжении веков люди считали, что n 3 — это самый быстрый способ умножения матриц. По имеющимся сведениям, в 1969 году Фолькер Штрассен намеревался доказать, что невозможно умножить матрицы 2 х 2, используя менее восьми умножений. Видимо, он все-таки не смог найти доказательства, а через некоторое время и понял почему: на самом деле, существует способ сделать это с помощью семи умножений!
Штрассен придумал сложный набор соотношений, которые позволили заменить одно из этих восьми умножений 14 дополнительными сложениями. Может показаться, что разница совершенно незначительна, но она оправдывает себя, так как умножение вносит больший вклад, чем сложение. Найдя способ избавиться от одного умножения для маленьких матриц 2 х 2, Штрассен открыл возможность, которую он мог использовать при умножении бOльших матриц.
«Это крошечное изменение приводит к огромным улучшениям в работе с большими матрицами», — говорит Уильямс.


Вирджиния Василевска Уильямс из Массачусетского технологического института и Джош Алман из Гарвардского университета открыли самый быстрый способ перемножения двух матриц за n 2.3728596 шагов. Джаред Чарни; Ричард Т.К. Хоук
Предположим, вы хотите перемножить пару матриц 8 х 8. Один из способов сделать это — разбить каждую большую матрицу на четыре матрицы размером 4 х 4 так, чтобы каждая имела по четыре элемента. Поскольку элементы матрицы также могут являться матрицами, вы можете считать исходные матрицы парой матриц 2 х 2, каждый из четырех элементов которых сам по себе является матрицей 4 х 4. Посредством некоторых манипуляций каждая из этих матриц размером 4 х 4 может быть разбита на четыре матрицы размером 2 х 2.
Смысл этого многократного разбиения больших матриц на более мелкие заключается в том, что можно снова и снова применять алгоритм Штрассена к меньшим матрицам и с помощью его метода сокращать количество шагов на каждом этапе. В целом алгоритм Штрассена увеличил скорость умножения матриц с n 3 до n 2.81 мультипликативных шагов.
Следующий важный шаг в развитии идеи произошел в конце 1970-х, когда появился принципиально новый подход к решению этой задачи. Он подразумевает перевод матричного умножения в другую вычислительную задачу линейной алгебры с использованием объектов, называемых тензорами. Тензоры, используемые в этой задаче, представляют собой трехмерные массивы чисел, состоящие из множества различных частей, каждая из которых выглядит как небольшая задача на умножение матриц.
Умножение матриц и эта задача, связанная с тензорами, в определенном смысле эквивалентны друг другу, но для решения последней исследователи уже имели более быстрые процедуры. Таким образом, перед ними встала задача определить «обменный курс» между ними: Матрицы какого размера можно перемножить при тех же вычислительных затратах, которые требуются для решения тензорной задачи?
«Это очень распространенная в теоретической информатике концепция: преобразовывать задачи и проводить аналогию между ними, чтобы показать, что они одинаково простые или сложные», — сказал Алман.
В 1981 году Арнольд Шёнхаге использовал этот подход, чтобы доказать, что умножение матриц возможно выполнить за n 2.522 шагов. Позднее Штрассен назвал этот подход «лазерным методом» (laser method).
За последние несколько десятилетий каждое улучшение в процессе умножения матриц происходило за счет усовершенствования лазерного метода, поскольку исследователи находили все более эффективные способы трансформации задачи. В своем новом доказательстве Алман и Уильямс стирают различие между 2 задачами и показывают, что уменьшить число умножений возможно. «В целом Джош и Вирджиния нашли способ применить машинные вычисления в рамках лазерного метода и получили лучшие на настоящий момент результаты», — сказал Генри Кон из Microsoft Research.
Но, несмотря на все эти гонки и победы, становится ясно, что в случае с этим подходом действует закон убывающей доходности, или убывающей отдачи. Скорее всего, усовершенствование Алмана и Уильямс почти полностью исчерпало возможности лазерного метода, но так и не позволило достичь конечной теоретической цели.
«Маловероятно, что получится приблизиться ко второй степени, используя это семейство методов», — отметил Уманс.
Для этого потребуется открытие новых методов и стойкая вера в то, что это вообще возможно.
Уильямс вспоминает один из разговоров со Штрассеном об этом: «Я спросила его, считает ли он, что возможно получить вторую степень для матричного умножения, и он ответил: «Нет, нет, нет, никогда!».



