Морти, мы в UltraHD! Как посмотреть любой фильм в 4K, дорисовав его через малоизвестную нейросеть
Наверное, вы слышали про технологию Яндекса DeepHD, с помощью которой они как-то раз улучшили качество советских мультфильмов. Увы, в публичном доступе ее еще нет, а у нас, рядовых программистов, вряд ли найдутся силы написать свое решение. Но лично мне, как обладателю Retina-дисплея (2880х1800), недавно очень захотелось посмотреть «Рика и Морти». Какого же было мое разочарование, когда я увидел, как мыльно на этом экране выглядит 1080р, в котором существуют оригиналы этого мультсериала! (это прекрасное качество и обычно его вполне достаточно, но поверьте, ретина так устроена, что анимация с ее четкими линиями в 1080р выглядит мыльновато, словно 480р на FHD-мониторе)
Я твердо решил, что хочу увидеть этот мультсериал в 4К, хотя и совершенно не умею писать нейросети. Однако решение было найдено! Любопытно, что нам даже не придется писать код, понадобится лишь
100 ГБ места на диске и немного терпения. А результат — четкое изображение в 4К, которые выглядит достойнее, чем любая интерполяция.
Подготовка
Во-первых, надо сразу понять, что в открытом доступе нет технологии по увеличению видео с помощью нейросетей. Вообще. Но зато есть несколько проектов, которые способны увеличивать фотографии. А раз так, давайте перекодируем наше видео в огромную кучу кадров!
Это можно сделать через Adobe Premiere Pro или другую программу для работы с видео, но я уверен, что такая установлена далеко не у всех. Поэтому давайте воспользуемся консольной утилитой ffmpeg. Я взял первую серию первого сезона, и понеслось:
Справедливый вопрос. Дело в том, что 31 000 PNG, которые бы мы получили бы на выходе, весили умопомрачительно много. Настолько много, что можно незначительно пожертвовать качеством.
Подождав примерно 10 минут, мы получим большущую папку с изображениями. У меня она заняла 26 ГБ. 
Осталось обработать каждый из этих кадров!
Как будем обрабатывать?
Я нашел три варианта, работающих более-менее нормально — это небезизвестный Let’s Enhance, waifu2x (натренирован на аниме) и Mail.ru Vision.
Чуть позже я обязательно покажу примеры.
Mail.ru Vision и Let’s Enhance неплохо обрабатывали изображения, но они, к сожалению, не опенсорсные, то есть для обработки 31000 картинок нам придется писать создателям на почту и, вероятно, немало заплатить. Поэтому я пригляделся к оставшемуся waifu2x, но он не порадовал меня качественным результатом, были шумы и нечеткости. Все-таки «Рик и Морти» — это не аниме.
Я уже было отчаялся бесконечно листать Github и тематические форумы, но… Спасение вдруг пришло! Нашелся вариант, который работает на машине локально, обрабатывает картинку меньше, чем за секунду, и показывает отличное качество. И вы не поверите, кто в очередной раз пришел нам на помощь!
И нет, я не буду рассказывать true story о том, как там можно парочкой фильтров сделать хорошую картинку. Adobe действительно натренировали самую настоящую нейросеть, которая при масштабировании внутри программы может дорисовать изображение!
Для начала нужно открыть исходное изображение, затем перейти через верхнее меню в Изображение > Размер изображения… и выбрать ресамплинг «Сохранение Деталей 2.0».
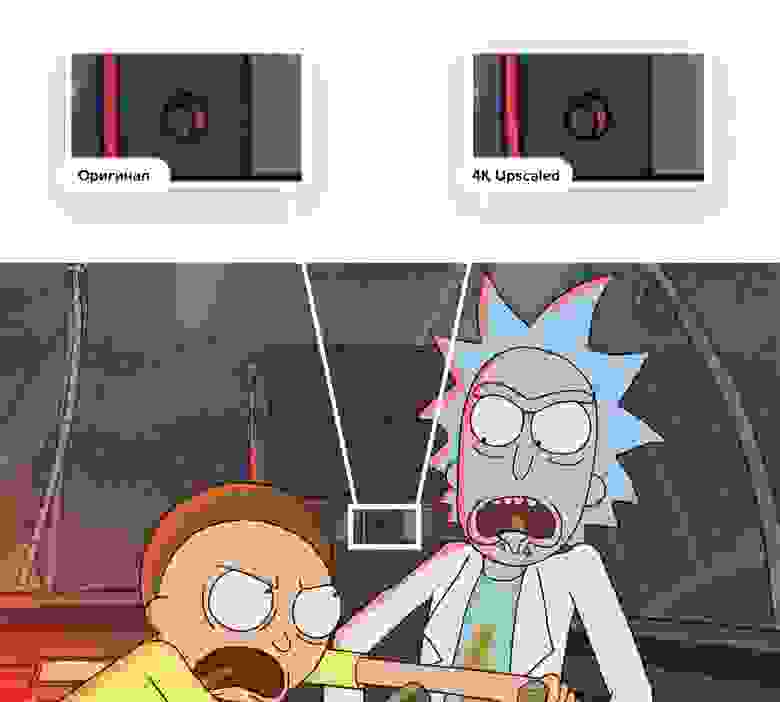
Результат приятно удивил! Пожалуй, впереди только Let’s Enhance. Вот и обещанное сравнение (исходное изображение приближено примерно в 8 раз):

— И что теперь, вручную обрабатывать каждый кадр через фотошоп?
Конечно, нет! В фотошопе есть инструмент Actions, который позволяет сначала записать последовательность действий, а потом применить ее на целую папку с изображениями. Не буду расписывать весь процесс, он легко гуглится.
Я оставил свой ноутбук обрабатывать тридцать одну тысячу кадров на ночь по шаблону «сделай апскейл в два раза и сохрани». Проснулся утром — все готово! Еще одна папка с кучей кадров, но теперь уже в 4К и с размером в 82 ГБ.
Назад, в видео
Нам снова поможет ffmpeg.
Понимаем, что мы совсем забыли про аудиодорожку, и достаем ее из оригинального файла:
А потом скидываем саунд в папку со всеми 4К-кадрами. Все наши труды прошли не зря, мы готовы к финальной склейке!
Как Яндекс применил компьютерное зрение для повышения качества видеотрансляций. Технология DeepHD
Когда люди ищут в интернете картинку или видео, они часто прибавляют к запросу фразу «в хорошем качестве». Под качеством обычно имеется в виду разрешение — пользователи хотят, чтобы изображение было большим и при этом хорошо выглядело на экране современного компьютера, смартфона или телевизора. Но что делать, если источника в хорошем качестве просто не существует?
Сегодня мы расскажем читателям Хабра о том, как с помощью нейронных сетей нам удается повышать разрешение видео в режиме реального времени. Вы также узнаете, чем отличается теоретический подход к решению этой задачи от практического. Если вам не интересны технические детали, то можно смело пролистать пост – в конце вас ждут примеры нашей работы.
В интернете много видеоконтента в низком качестве и разрешении. Это могут быть фильмы, снятые десятки лет назад, или трансляции тв-каналов, которые по разным причинам проводятся не в лучшем качестве. Когда пользователи растягивают такое видео на весь экран, то изображение становится мутным и нечётким. Идеальным решением для старых фильмов было бы найти оригинал плёнки, отсканировать на современном оборудовании и отреставрировать вручную, но это не всегда возможно. С трансляциями всё ещё сложнее – их нужно обрабатывать в прямом эфире. В связи с этим наиболее приемлемый для нас вариант работы — увеличивать разрешение и вычищать артефакты, используя технологии компьютерного зрения.
В индустрии задачу увеличения картинок и видео без потери качества называют термином super-resolution. На эту тему уже написано множество статей, но реалии «боевого» применения оказались намного сложнее и интереснее. Коротко о главных проблемах, которые нам пришлось решать в собственной технологии DeepHD:
Выбор технологии
В последние годы использование нейронных сетей привело к значительным успехам в решении практически всех задач компьютерного зрения, и задача super-resolution не исключение. Наиболее перспективными нам показались решения на основе GAN (Generative Adversarial Networks, генеративные соперничающие сети). Они позволяют получить фотореалистичные изображения высокой чёткости, дополняя их недостающими деталями, например прорисовывая волосы и ресницы на изображениях людей.
В самом простом случае нейронная сеть состоит из двух частей. Первая часть – генератор – принимает на вход изображение и возвращает увеличенное в два раза. Вторая часть – дискриминатор – получает на вход изображение, сгенерированные и “настоящие”, и пытается отличить друг от друга.
Подготовка обучающего множеств
Для обучения мы собрали несколько десятков роликов в UltraHD-качестве. Сначала мы уменьшили их до разрешения 1080p, получив тем самым эталонные примеры. Затем мы уменьшили эти ролики ещё вдвое, попутно сжав с разным битрейтом, чтобы получить что-то похожее на реальное видео в низком качестве. Полученные ролики мы разбили на кадры и в таком виде использовали для обучения нейронной сети.
Деблокинг
Конечно же, нам хотелось получить end-to-end-решение: обучать нейросеть генерировать видео высокого разрешения и качества сразу из оригинального. Однако GAN’ы оказались очень капризны и постоянно пытались уточнять артефакты сжатия, а не устранять их. Поэтому пришлось разбить процесс на несколько этапов. Первый – подавление артефактов сжатия видео, также известный как деблокинг.
Пример работы одного из методов деблокинга:

На этом этапе мы минимизировали среднеквадратичное отклонение между сгенерированным и исходным кадром. Тем самым мы хоть и увеличивали разрешение изображения, но не получали реального повышения разрешения за счёт регрессии к среднему: нейросеть, не зная, в каких конкретно пикселях проходит та или иная граница на изображении, была вынуждена усреднять несколько вариантов, получая размытый результат. Главное, чего мы добились на этом этапе – устранение артефактов сжатия видео, так что генеративной сети на следующем этапе нужно было только повысить чёткость и добавить недостающие мелкие детали, текстуры. После сотен экспериментов мы подобрали оптимальную по соотношению производительности и качества архитектуру, отдалённо напоминающую архитектуру DRCN:
Основная идея такой архитектуры состоит в желании получить максимально глубокую архитектуру, при этом не получив проблем со сходимостью при её обучении. С одной стороны, каждый следующий свёрточный слой извлекает всё более сложные признаки входного изображения, что позволяет определять, что за объект находится в данной точке изображения и восстанавливать сложные и сильно повреждённые детали. С другой стороны, расстояние в графе нейронной сети от любого её слоя до выхода остаётся небольшим, благодаря чему улучшается сходимость нейросети и появляется возможность использовать большое количество слоёв.
Обучение генеративной сети
За основу нейронной сети для повышения разрешения мы взяли архитектуру SRGAN. Прежде чем обучать соревновательную сеть, нужно предобучить генератор – обучить его тем же способом, что и на этапе деблокинга. В противном случае в начале обучения генератор будет возвращать только шум, дискриминатор сразу начнёт «выигрывать» – легко научится отличать шум от реальных кадров, и никакого обучения не получится.
Далее обучаем GAN, но и тут есть свои нюансы. Нам важно, чтобы генератор создавал не только фотореалистичные кадры, но и сохранял имеющуюся на них информацию. Для этого к классической архитектуре GAN’а мы добавляем контентную функцию потерь (content loss). Она представляет собой несколько слоёв нейросети VGG19, обученной на стандартном датасете ImageNet. Эти слои преобразуют изображение в карту признаков, которая содержит информацию о содержимом изображения. Функция потерь минимизирует расстояние между такими картами, полученными из сгенерированного и исходного кадров. Также наличие такой функции потерь позволяет не испортить генератор на первых шагах обучения, когда дискриминатор ещё не обучен и выдает бесполезную информацию.
Ускорение нейросети
Всё шло хорошо, и после цепочки экспериментов мы получили неплохую модель, которую уже можно было применять к старым фильмам. Однако для обработки потокового видео она все ещё была слишком медленной. Оказалось, что просто уменьшить генератор без существенной потери качества итоговой модели нельзя. Тогда нам на помощь пришёл подход knowledge distillation («дистилляция» знаний). Этот метод предусматривает обучение более лёгкой модели таким образом, чтобы она повторяла результаты более тяжёлой. Мы взяли множество реальных видео в низком качестве, обработали их полученной на предыдущем шаге генеративной нейросетью и обучили более лёгкую сеть получать из тех же кадров такой же результат. За счёт этого приёма мы получили сеть, которая не очень сильно уступает по качеству исходной, но быстрее её в десятки раз: на обработку одного телеканала в разрешении 576p требуется одна карта NVIDIA Tesla V100.
Оценка качества решений
Пожалуй, самый сложный момент при работе с генеративными сетями – это оценка качества полученных моделей. Здесь нет понятной функции ошибки, как, например, при решении задачи классификации. Вместо этого мы знаем только точность дискриминатора, которая никак не отражает интересующее нас качество генератора (хорошо знакомый с этой сферой читатель мог бы предложить использовать метрику Вассерштайна, но, к сожалению, у нас она давала заметно более плохой результат).
Решить эту проблему нам помогли люди. Мы показывали пользователям сервиса Яндекс.Толока пары изображений, одно из которых было исходным, а другое – обработанным нейросетью, либо оба были обработанными разными версиями наших решений. За вознаграждение пользователи выбирали более качественное видео из пары, так мы получали статистически значимое сравнение версий даже при сложно различимых глазом изменениях. Наши итоговые модели одерживают победу в более чем 70% случаев, что достаточно много, учитывая, что пользователи тратят на оценку пары видео всего несколько секунд.
Интересным результатом также стал тот факт, что видео в разрешении 576p, увеличенное технологией DeepHD до 720p, выигрывает у такого же оригинального видео с разрешением 720p в 60% случаев – т.е. обработка не только повышает разрешение видео, но и улучшает его визуальное восприятие.
Примеры
Весной мы испытали технологию DeepHD на нескольких старых фильмах, посмотреть которые можно на КиноПоиске: «Радуга» Марка Донского (1943), «Летят журавли» Михаила Калатозова (1957), «Дорогой мой человек» Иосифа Хейфица (1958), «Судьба человека» Сергея Бондарчука (1959), «Иваново детство» Андрея Тарковского (1962), «Отец солдата» Резо Чхеидзе (1964) и «Танго нашего детства» Альберта Мкртчяна (1985).
Разница между версиями до и после обработки особенно заметна, если вглядываться в детали: изучать мимику героев на крупных планах, рассматривать фактуру одежды или рисунок ткани. Удалось компенсировать и некоторые недостатки оцифровки: например, убрать пересветы на лицах или сделать более заметными предметы, размещённые в тени.
Позднее технология DeepHD стала использоваться для улучшения качества трансляций некоторых каналов в сервисе Яндекс.Эфир. Распознать такой контент легко по метке dHD.
Теперь на Яндексе в улучшенном качестве можно посмотреть «Снежную королеву», «Бременских музыкантов», «Золотую антилопу» и другие популярные мультики киностудии «Союзмультфильм». Несколько примеров в динамике можно увидеть в ролике:
Для требовательных к качеству изображения зрителей разница будет особенно заметной: изображение стало более резким, лучше видны листья деревьев, снежинки, звёзды на ночном небе над джунглями и другие мелкие детали.
Полезные ссылки
Jiwon Kim, Jung Kwon Lee, Kyoung Mu Lee Deeply-Recursive Convolutional Network for Image Super-Resolution [arXiv:1511.04491].
Christian Ledig et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network [arXiv:1609.04802].
Mehdi S. M. Sajjadi, Bernhard Schölkopf, Michael Hirsch EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis [arXiv:1612.07919].
NeuroHD — технология, повышающая разрешение видео и восстанавливающая детали
Сервис «VK Видео» запустил новую технологию NeuroHD для повышения качества видео в социальных сетях «ВКонтакте» и «Одноклассники». Она в режиме реального времени повышает разрешение воспроизводимых роликов в два раза, восстанавливает детали и убирает шумы и дефекты, появившиеся в результате сжатия ролика.
 Демонстрация работы NeuroHD
Демонстрация работы NeuroHD
В основе NeuroHD лежит две нейросети: одна генерирует увеличенные изображения, а вторая проверяет сгенерированные изображения на соответствие оригиналу. Чтобы избежать так называемых «плавающих артефактов», дополнительно используются элементы временной консистентности, учитывающие информацию о соседних фрагментах ролика.
«Важную роль в обучении нейросети для достижения высокого качества видеокартинки сыграл специально сконструированный набор данных для обучения. Многомиллионная библиотека «VK Видео» позволила эффективно повышать разрешение видео разных форматов: профессиональных и любительских, горизонтальных и вертикальных, динамических и статичных, длиной в часы или несколько секунд», — говорится в блоге разработчиков.
Улучшенные с помощью нейросети видео уже доступны в ряде групп и публичных страниц «ВКонтакте». Администратор любого сообщества может отправить запрос, чтобы улучшить качество видео. В перспективе технология будет применена ко всем видео, представленным на платформе, в том числе и загруженным самими пользователями.
19 отличных бесплатных нейросетей
К 2019 году искусственные нейронные сети стали чем-то большим, чем просто забавная технология, о которой слышали только гики. Да, среди обычных людей мало кто понимает что из себя представляют нейросети и как они работают, но проверить действие подобных систем на практике может каждый – и для этого не нужно становиться сотрудником Google или Facebook. Сегодня в Интернете существуют десятки бесплатных проектов, иллюстрирующих те или иные возможности современных ИНС, о самых интересных из них мы и поговорим.
Из 2D в 3D
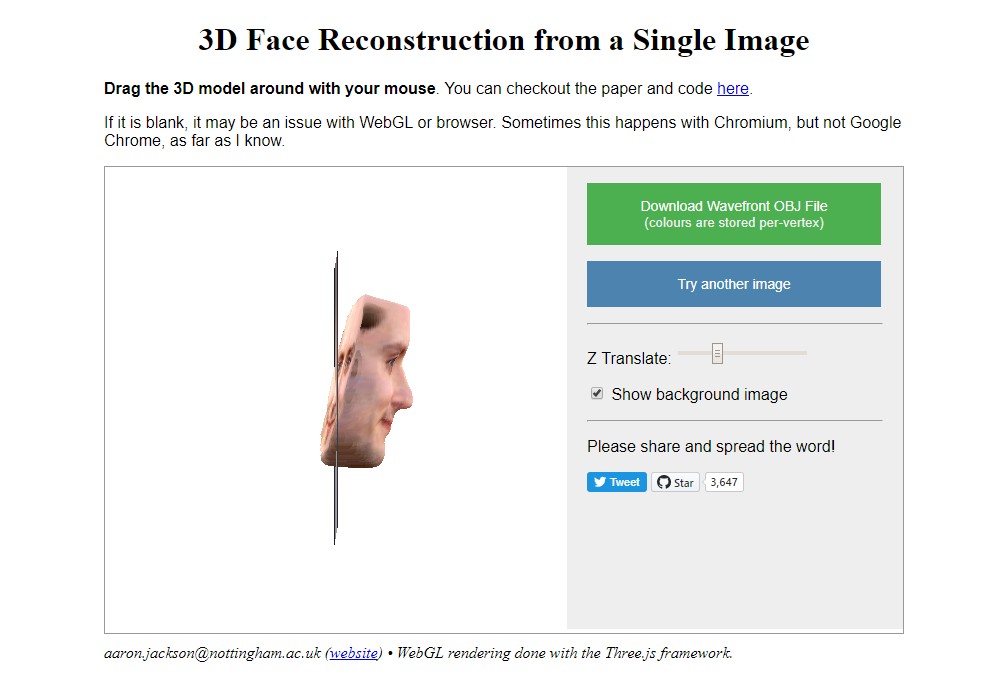
На этом сервисе вы сможете вдохнуть новую жизнь в свои старые фотографии, сделав их объемными. Весь процесс занимает меньше минуты, необходимо загрузить изображение и через несколько секунд получить 3D-модель, которую можно покрутить и рассмотреть во всех деталях. Впрочем, есть два нюанса — во-первых, фотография, должна быть портретной (для лучшего понимания требований на главной странице сайта представлены наиболее удачные образцы снимков, которые ранее загружали другие пользователи; во-вторых, детализация получаемой модельки зачастую оставляет желать лучшего, особенно, если фотография в низком разрешении. Однако авторы разрешают не только ознакомиться с результатом в окне браузера, но и скачать получившийся файл в формате obj к себе на компьютер, чтобы затем самостоятельно его доработать.
Нейминг брендов
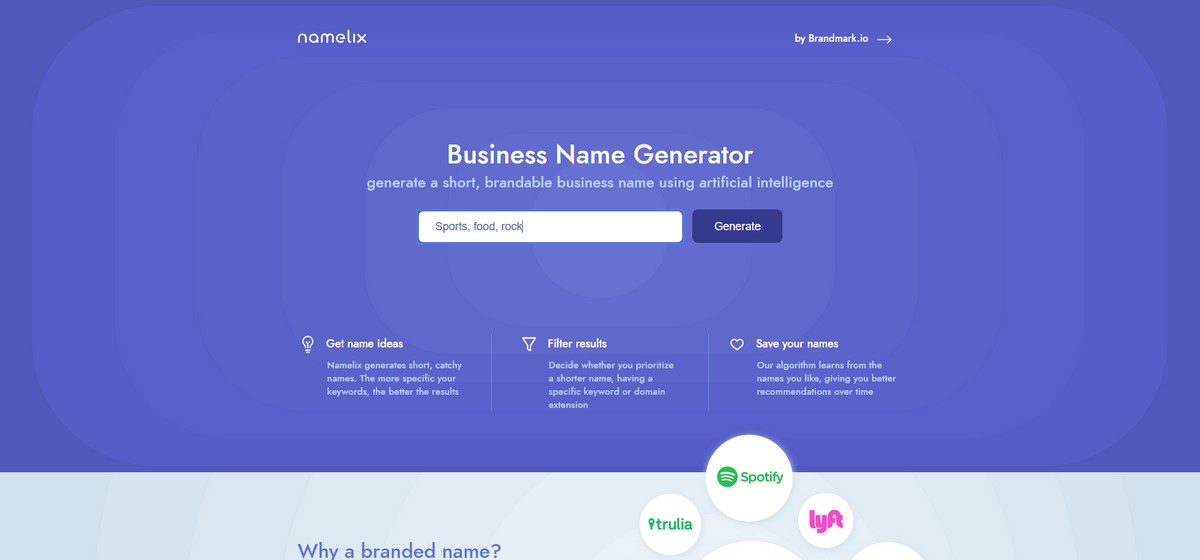
Придумали крутую идею для стартапа, но не можете определиться с именем для будущей компании? Достаточно вбить несколько ключевых слов, задать длину названия в символах и готово! В общем, больше не нужно искать на фрилансе людей, которые будут решать такой личный вопрос, как наименование дела всей вашей жизни.
Выбор досуга

Пересмотрели все интересные вам фильмы, прочли все достойные книги и не знаете чем занять вечер? Система рекомендаций от специалиста по искусственному интеллекту Марека Грибни расскажет как увлекательно и с пользой провести свободное время. Для корректной работы сервиса вас сперва попросят указать ваши любимые произведения в кинематографе, литературе, музыке или живописи.
Рай для искусствоведа
Google специально для поклонников современного (и не только) искусства запустила проект Google Arts & Culture, в котором можно подобрать произведения по вашему вкусу как от малоизвестных, так и от малоизвестных авторов. Большая часть контента здесь на английском, но если вы не дружите с языками, можно воспользоваться встроенным переводчиком.
Озвучивание картинок
Японская студия Qosmo разработала очень необычную нейросеть Imaginary Soundscape, которая воспроизводит звук, соответствующий тому или иному изображению. В качестве источника информации вы можете указать ссылку на любую картинку в Интернете, загрузить свой файл либо выбрать случайную локацию на Google Maps.
Не умеешь рисовать – тогда тебе к нам!

Если вы пробовали использовать рукописный ввод на своем смартфоне, эта нейросеть покажется вам до боли знакомой: она превращает любые каракули в аккуратные 2D-рисунки.
Генерация людей

Thispersondoesnotexist – это один самых известных AI-проектов. Нейросеть, созданная сотрудником Uber Филиппом Ваном, выдает случайное изображение несуществующего человека при каждом обновлении страницы.
Генерация… котов

Тот же автор разработал аналогичный сайт, генерирующий изображения несуществующих котов.
Быстрое удаление фона
Часто ли вам приходится тратить драгоценное время на удаление бэкграунда с фотографий? Даже если регулярно такой необходимости не возникает, следует на всякий случай знать о возможности быстрого удаления фона с помощью удобного онлайн-инструмента.
Написать стихотворение

Компания ‘Яндекс’, известная своей любовью к запуску необычных русскоязычных сервисов, имеет в своем портфолио сайт, где искусственный интеллект составляет рандомные стихотворения из заголовков новостей и поисковых запросов.
Окрашивание черно-белых фотографий

Colorize – это также российская нейросеть, возвращающая цвета старым черно-белым снимкам. В бесплатной версии доступно 50 фотографий, если вам нужно больше, можете приобрести платный аккаунт с лимитом в десять тысяч изображений.
Апскейлинг фото
Лет 10-15 назад камеры мобильных устройств не отличались высоким разрешением, и слабый сенсор в телефоне никак не мог справиться с детализированной картиной окружающего мира. Теперь же, если вы захотите повысить разрешение своих старых фотографий, это можно сделать на сервисах вроде Bigjpg и Let’s Enhance, которые позволяют увеличить размер изображения без потери в качестве.
Чтение текста голосом знаменитостей

Благодаря высоким технологиям, сегодня у вас есть возможность озвучить любую фразу голосом самых известных в мире людей. Все просто: пишите текст и выбираете человека (среди последних — Дональд Трамп, Тейлор Свифт, Марк Цукерберг, Канье Уэст, Морган Фриман, Сэмюель Л Джексон и другие).
Описание фотографий
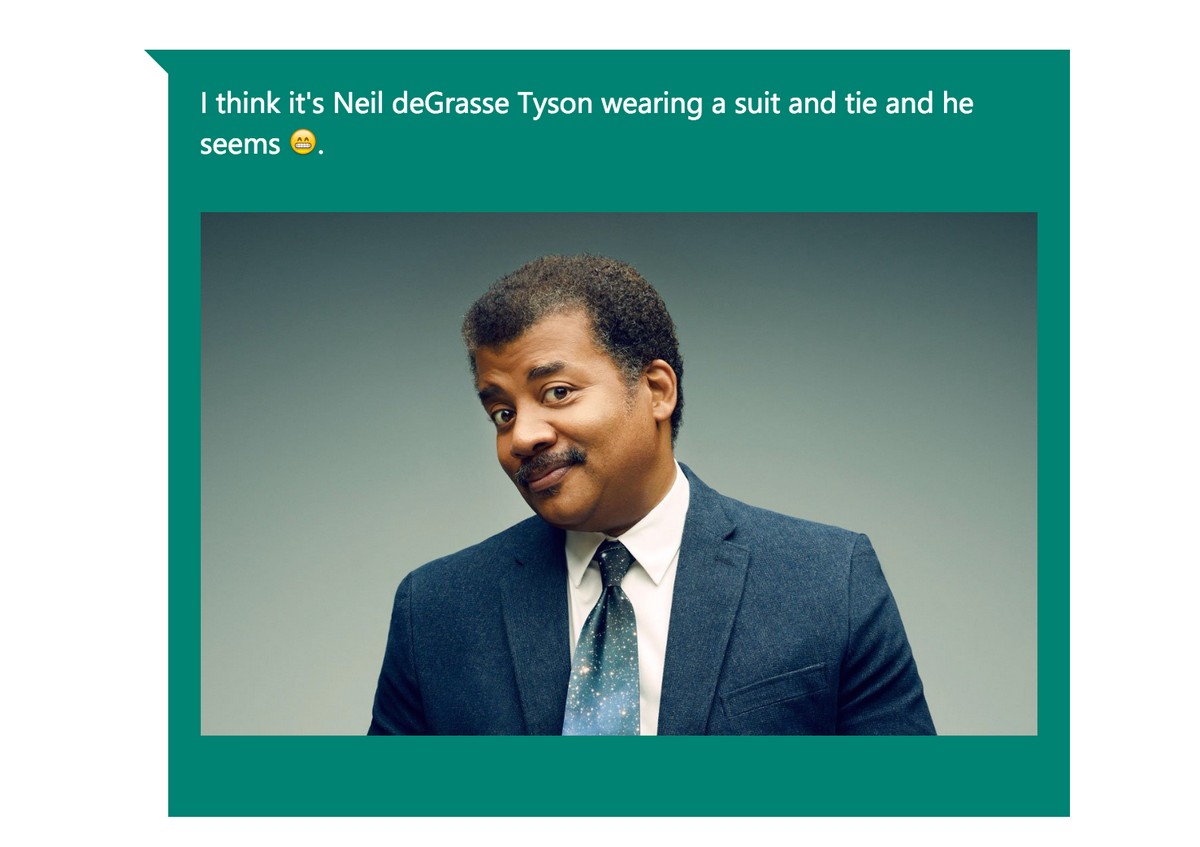
Казалось бы, искусственный интеллект должен быть способен без труда описать любую, даже самую сложную картинку. Но это вовсе не так, обучить ИИ распознавать отдельные образы действительно относительно просто, а вот заставить компьютер понимать общую картину происходящего на изображении, очень сложная задача. У Microsoft получилось с ней справиться, и ее CaptionBot без труда скажет, что вы ему показываете.
Музыкальная шкатулка
Напоследок расскажем о целой пачке нейросетей от Google, первая из них – Infinite Drum Machine. Открыв страницу приложения, вы увидите своеобразную карту, на которой находятся самые разнообразные звуки. С помощью круглых манипуляторов можно изменять сочетание элементов, если получившийся набор покажется вам бессмысленным, нажмите кнопку Play в нижней части экрана и звуковая картина сложится сама собой.
Птичий хор
Если предыдущий сервис может оказаться полезным для, например, диджеев или обычных музыкантов, то польза от управления голосами десятков тысяч певчих птиц довольно сомнительна. Кстати, коллекция звуков для Bird Sounds собиралась орнитологами со всего мира на протяжении нескольких десятилетий.
Виртуальный пианист
В A. I. Duet пользователю предлагается сыграть какую-нибудь мелодию на пианино, а искусственный интеллект попробует самостоятельно закончить композицию, подобрав наиболее логичное и гармоничное продолжение.
Распознавание рисунков
Еще во время первых экспериментов с нейросетями в середине прошлого века основной задачей машинного обучения было распознавание визуальных образов. Спустя десятки лет эта технология выбралась из лабораторий и доступна всем желающим: на сайте quickdraw.withgoogle.com/ вам предложат быстро рисовать простые наброски определенных предметов, при этом ИИ будет все время комментировать происходящее на экране синтезированной речью.
Объяснение логики машинного обучения
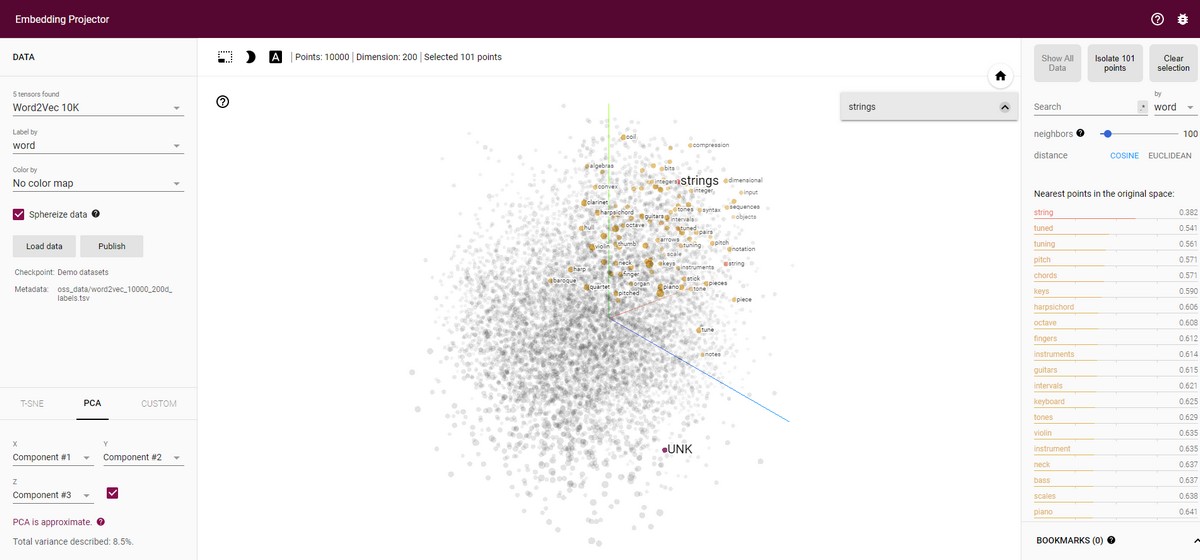
Проект Visualizing High-Dimensional Space (“Визуализация многомерного пространства”) создавался для того, чтобы объяснить простым людям и начинающим разработчикам, как работают нейросети. Когда ИИ, оперируя большими базами данных, получает информацию (например, вашу фотографию, введенную фразу или только что нарисованное изображение), он сравнивает входящие данные с теми, что у него уже есть. VHDS наглядно демонстрирует корреляцию одного лишь выбранного вами слова с миллионами аналогичных понятий.



